Technical Documentation
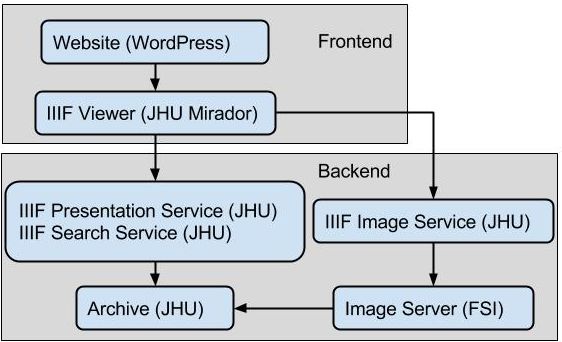
The infrastructure of the Archaeology of Reading (AOR) consists of layered components separated by interfaces. The diagram below shows those components and their dependencies. Frontend components are delivered by a web browser to the user. Backend components are responsible for preserving data and delivering that data to front end components in the appropriate form. Many of these components already existed and were reused or enhanced to support AOR.
AOR takes advantage of the International Image Interoperability Framework (IIIF) to provide a web interface. IIIF is a community-developed framework for describing image-based web resources such as digitized books. Applications built on top of the well-defined IIIF APIs can be used with any content described by IIIF. Mirador is an IIIF application that provides a web interface for browsing, viewing, and interacting with IIIF content.
AOR shares many requirements with other projects we have worked on such as the Roman de la Rose Digital Library and the Christine de Pizan Digital Scriptorium. For example, all of these projects involve both preserving digitized books and making them accessible. These similarities make it possible for AOR to use the same archive as those other projects. It also means that enhancements made for AOR are available to other collections in the archive. For example, IIIF support is available to every digitized book collection in the archive.
The archive component manages storage and provides tools and interfaces for depositing data and validating stored data. The image server is the commercial FSI Server. FSI Server indexes images in the archive in order to provide efficient tiling and scaling operations on them. The IIIF Image service implements the IIIF Image API by using the image server. The IIIF Presentation service implements the IIIF Presentation API by transforming data in the archive from the archival model to the IIIF Presentation model on demand. The IIIF viewer is a version of Mirador, which has been customized and integrated into a WordPress site. The WordPress site manages the project blog and other project pages.
Mirador supported almost all of our user interface requirements with the exception of transcription viewing and search, which required some customization. The scholars on the AOR team produced detailed transcriptions of all of Harvey’s annotations and wished to see those transcriptions presented alongside the corresponding page images. We modeled those transcriptions as IIIF Annotations with HTML bodies targeted at the page image and added a sidebar to display them.
The scholarly members of the team also needed support for complicated queries across the corpus as well as within a given book. An example query would be to return all pages in the corpus having an underlined Latin word and a marginalia translation that includes an English phrase. The IIIF Content Search API does not support such queries. We designed a IIIF search service to meet those needs for AOR and to be flexible enough for other collections. We added a search tab to the sidebar where searches could be constructed and search results browsed.
All relevant project code can be accessed via the AOR GitHub repository as well as throughout project documentation. All the metadata generated by the project have been packaged together into a data release that can be downloaded from the AOR website.