How to Do AOR Yourself
From the very start of the project, many people have been asking us how they can leverage the AOR technology and apply it to their own research materials. It is impossible to provide a one-size-fits-all blueprint, since particular aspects of this project are determined by a number of contingent factors, including the research interests of the scholars involved, the preexisting technological infrastructure at Johns Hopkins University in which AOR is embedded, and the particular solutions developed by the team to overcome specific technological and scholarly hurdles. We can, however, provide a basic outline of the project and provide a list of key components that are necessary to get a project like AOR up and running. What follows, then, is such a list of core components as well as a description of how these components are brought together in what we call the AOR digital research environment.
AOR consists of two closely interwoven yet clearly distinguishable strands, one humanistic and one technological. Simply put, the humanistic strand comprises the creation of content that populates the AOR digital research environment and that users can employ in pursuit of their own research questions and interests. The main component of the humanist strand is the carefully created selection of thirty-six books annotated by John Dee and Gabriel Harvey. All the interventions these readers made in their books have been captured in thousands of XML transcriptions. From this starting point, contextual essays and other documentation are primarily created to introduce the users to the books and their readers as well as to the functionalities of the AOR resource.
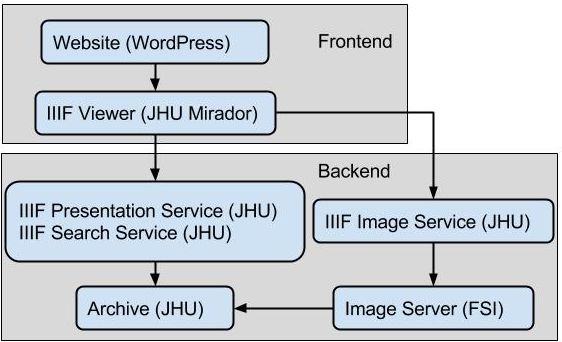
The principal aim of the technological stand is to create the infrastructure to archive and deliver the AOR data, in particular the XML transcriptions and the images of the digitized books, and to enable the user to interact with this data through a customized viewer enhanced with a set of bespoke functionalities. These include image manipulation and viewing, transcription viewing, robust search facilities, and the possibility to export research findings. Taken together, the outcomes of the humanistic and technological strands from the building blocks of the AOR digital research environment. However, while some building blocks are clearly visible (e.g., a viewer that displays images and transcriptions), others are more hidden (e.g., parts of the digital infrastructure, such as the image archive), which can make it difficult to discern the components that comprise a digital humanities project such as AOR. This document intends to unveil some of these hidden building blocks by describing them and their relation to more visible parts of the project.
The basic requirements necessary to execute a digital humanities project like AOR that makes use of the IIIF-standard are:
IIIF-compliant image server (e.g., IIIFServer)
IIIF-compliant viewer (e.g., Mirador)
Digital images
XML editor (e.g., Oxygen)
XML transcriptions
Metadata describing collections, books, and images.
Implementation of IIIF Presentation API (see below, section 2.2)
Website
In particular the implementation of the IIIF Presentation API may pose a problem. This API is responsible for translating the project metadata and transcriptions into a form understandable by a IIIF viewer and hence is very sensitive to those details. It may be hard to find an off-the-shelf implementation that does exactly what your project needs. The AOR implementation is available here, https://github.com/jhu-digital-manuscripts/rosa2, but requires deep technical knowledge to set up and use.
Humanities Content
1. Establish a Corpus
As explained in the contextual essays on Dee’s and Harvey’s libraries, the composition of the AOR corpora depended on a number of factors, including the costs of digitization, the availability of books, the books owned by partner institutions, and the particular research interests of the scholars involved. In part, though, the selection of some books depended on the extent to which they could further technological development in terms of the XML schema and particular functionalities of the modified AOR Mirador viewer.
2. Create Digital Images
In order to be able to display images of annotated books in a digital environment, books (or indeed historical documents of any kind) need to be digitized. In most cases, at least in our experience, the digitization of the books was done in situ, by the repositories themselves, but it also happened that we contracted a third party (UCL Digital Media in our case) to digitize a number of books from a particular repository for us. Whatever the precise arrangements may be, the involvement of various parties can cause differences in the quality of the images as well as rather widely varying digitization costs. However, by providing a set of ‘Image Digitization Specifications and Guidelines’, including the requirement that the images should have a resolution of 600 DPI, we tried to ensure a similarly high standard across the images. After digitization, all the images were shared among the team members: the scholars used the digital images to create transcriptions of all the reader interventions in these books, while the computer engineers ingested the images into their archive in order to make them available in the AOR viewer (see below, section 2.1).
3. Create XML Schema and Transcriptions
XML is a markup language and a widely used standard, both within and outside the humanities, for the creation of machine-readable documents of structured data. While many academic projects of various kinds make use of the guidelines created by the TEI (Text Encoding Initiative) for creating digital versions of mostly printed primary sources, we decided to create our own bespoke XML schema, in part due to the limitations of TEI in relation to capturing manuscript annotations in printed books. The resulting AOR schema is the outcome of a long iterative process in which we conceptualized the various types of reader interventions we encountered in the AOR corpora and, in close cooperation with the computer engineers of Johns Hopkins’s Data Research and Curation Center (DRCC), established the best way of capturing and structuring the data.
In general, we aimed to create a flexible, component-based schema that is relatively concise and possible to use intuitively. Moreover, we wanted to create a schema that was as neutral as possible, meaning that we tried to limit the number of editorial interventions when capturing the marginalia, aiming to create a dataset that would not be overly determined by our own assumptions, ideas, and interests. Last, we opted for a maximalist approach, capturing all the interventions made by Dee and Harvey in their books in such a way that the resulting dataset would not only allow us to answer our particular research questions but hopefully would also be of use to scholars from other, allied disciplines. All in all, what we wanted to avoid was the creation of a “black box”, a project which is inward-looking, concerns itself only with the research interests of the members of the project team, and does not situate itself in a galaxy of related digital humanities projects and resources. For more information on the XML schema and its development, see the Transcriber’s Manual. Sayeed Choudhury and Jaap Geraerts have also given two presentations on the iterative model of development adopted by AOR, recordings of which are available here and here.
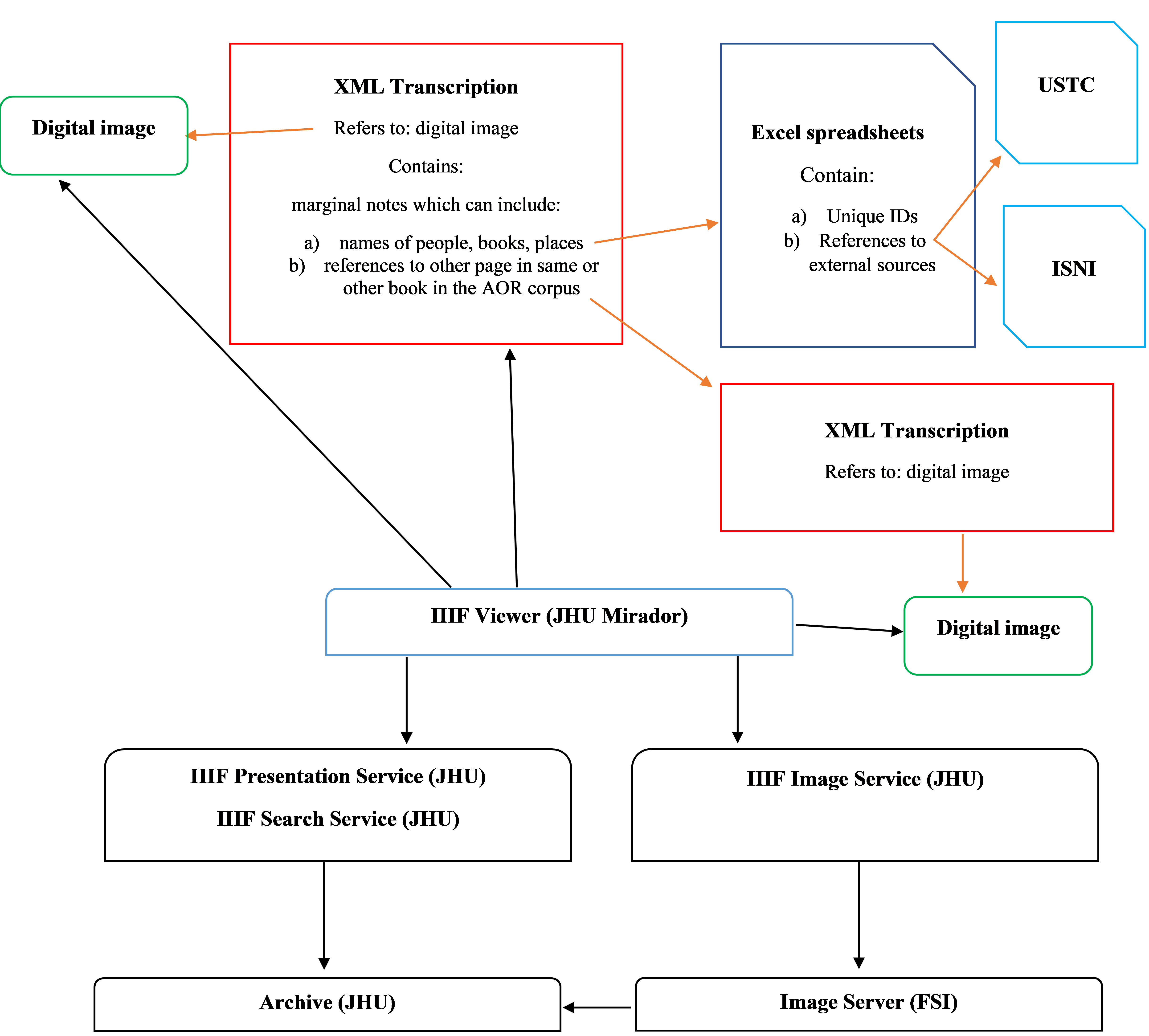
As a result of the close cooperation between humanist scholars and computer engineers, the XML schema is not only used to classify and capture reader interventions but also contains critical information to enable particular functionalities and features of the AOR viewer. For example, every transcription contains all the reader interventions visible on one specific digital image. In order to juxtapose the digital image and the transcription next to each other in the viewer, the file name of the digital image is recorded in the transcription, thus establishing a link between the two files. To offer another example: we wanted to be able to follow the pathways of early modern readers as they moved through their books. One way of doing this is to capture the cross-references—marginal notes such as “See p. 50 of this book”—and make them operational, that is, turn them into clickable links in the viewer. In order to do so, the XML schema not only had to capture the text of such marginal notes, but also add additional information (a unique Uniform Resource Identifiers, or URI, in this case) to establish the link from a particular page to another page (either in the same book or in another book). (See the Transcriber’s Manual, pp. 22-27 for more information on these ‘internal links’.) Hence the information in the XML transcriptions institutes some of the links which tie the different data sources of AOR together, as shown in the diagram below.
Technological Requirements
1. Institutional Archive
The underlying data making up the AOR collection exists as a hierarchy of files in the preservation storage. The directories represent books. The files in a directory are page images, transcriptions, and metadata describing the books. Custom tools are used to import new data into the archive, manage it, read it, and check it for integrity and consistency. The same tools are used to manage similar collections like that of the Digital Library of Medieval Manuscripts. This is a low-level and low-tech means of managing the data. Experts can simply use standard file system utilities; there is no user interface. The particular ways in which JHU manages the data are not important, but there needs to be some set of technology and practices to manage the data and preserve it.
In order for the data in the archive to be displayed in the AOR viewer, the images and metadata must be accessible, and there must be an actionable description of the collection (i.e., the AOR digitized corpora of books). This is done by taking advantage of the IIIF Framework. Images are made available through the IIIF Image API, while the IIIF Presentation API is used to describe the collection.
2. Implementation of IIIF Presentation API
The IIIF Presentation API is designed to describe image-based objects such as pages of digitized books. When given such a description, a IIIF viewer can produce a versatile user experience including a zoom/pan image viewer built on top of the IIIF Image API. The difficulty is producing a description based on the data in the archive. Moreover, because the IIIF Presentation API specification is so broad, a IIIF viewer may not display the information in quite the right way. Figuring out the most productive way to represent the collection in IIIF is an iterative process and likely requires the modification of an existing IIIF viewer in order to present the most user-friendly view of the collection.
One option is to create static descriptions which can then be served out by any web server. This requires one to do work to keep those descriptions up to date with the data in the archive. JHU sidesteps this problem and implements the IIIF Presentation API by dynamically converting the book descriptions in the archive to IIIF Presentation API-compliant descriptions (manifests). A web service transforms a book or collection in the JHU archive into a IIIF description of that object on demand. This is a transformation from the archival data model to the IIIF Presentation API data model. For example, the detailed AOR transcriptions describing interventions on a page become a sequence of IIIF annotations displayed in the sidebar of the viewer.
3. IIIF Search Service
IIIF has a built-in search service for running simple queries against IIIF annotations. This, however, is not sufficient to address the complex use cases designed by the scholars involved in AOR. Each AOR transcription comprises detailed information about the various reader interventions that are contained in the books in the AOR corpora. These reader interventions are classified into different categories such as marginalia, symbols, and drawings. Moreover, the data in these transcriptions consist of various languages and includes translations of non-English marginal annotations into English. We produced a custom search service that supports Boolean queries against these different categories and handles stemming in all the different languages. A custom widget was added to the customized Mirador viewer that uses this search service.
4. IIIF Image Server
IIIF has a specific protocol for accessing images that provides the functionality needed by zoom/pan user interfaces. For phase 1 of AOR we had implemented that protocol on top of the commercial FSI image server. For phase 2 it was decided to use a different commercial image server, IIIF Server, which natively supports that protocol. The IIIF Server answers requests about a hierarchy of jpeg 2000 images. In order for AOR images in our archive to accessible, we create a jpeg 2000 image for each one. This process can be automated, but may require custom encoding work in some cases.
The Viewer
1. IIIF and the Mirador Viewer
The International Image and Interoperability Framework (IIIF) is a relatively new and upcoming standard for storing, displaying, and sharing digital images. A large and continuously increasing number of academic and cultural institutions across the world have adopted this standard, and so has AOR. Mirador is one of the several IIIF-compliant viewers that is currently available. A community-based, open-source viewer, we selected the Mirador viewer because, in comparison to other IIIF-compliant viewers, it could be modified relatively easily to suit our use cases. The Mirador viewer and its functionalities are frequently updated and refined. However, it was necessary to modify and customize the existing version of the Mirador viewer in order to display the rich data contained in the AOR XML transcriptions and to launch searches across the AOR dataset. In order to do so, DRCC created a transcription and search widget, consisting of two panels. In one panel the transcriptions and translations of marginal notes and symbols can be viewed, whereas the other panel provides users with the opportunity to execute simple string searches and more complicated query-based searches. The latter kind of search is possible because of the structured data generated in the XML transcriptions. Here the design of the XML schema has a direct relation to how and what a user can search for. Another important modification of the Mirador viewer is the possibility to record one’s research steps and export them as a plain html file or as a RMap linked data graph.
The content displayed in the Mirador viewer, both in terms of the images, the transcription data, and the information about the books, is derived from various sources (see also the diagrams above and below). The IIIF image API retrieves images from the IIF-compliant images server, while the IIIF presentation API and IIIF search service interacted with information stored in the JHU archive. In addition, various Microsoft Excel spread sheets contain the names of people, titles of books, and names of geographical locations tagged in the XML transcriptions (all these sheets are available here). The standardized names function as standard identifiers, while their variant spellings are recorded as well, making searches for a particular entity across the AOR dataset possible. Another Excel spread sheet comprises bibliographical information about the books in our corpus. Part of this information is displayed in the viewer (e.g. on the gallery page and in the metadata panel). In short, within the Mirador viewer data which is stored in different places is brought together in order to provide the user with all the information she or he needs.
Project Website
The AOR WordPress site is the central point of access for the project. Users can go to the AOR viewer from this site or can consult a range of contextual and interpretative essays, blogs, and other documentation. The site is also host to the most recent and several older data releases and contains links to the project’s online GitHub repository containing the XML transcriptions and schema, as well as to JHU’s repository, where all the code used for AOR is stored and made publicly available. In addition to being the public face of the project, the website at the same time functions as a central hub from which the different components of the project can be explored.