In a previous blog entry, we talked about how Chris Geekie taught a class studying an annotated Hamlet prompt book from 1676, where the students would study the prompt book in a similar way to how Gabriel Harvey’s marginal annotations were studied in the AOR project. This summer course, funded by the Andrew W. Mellon Foundation, was designed to introduce local community college students to digital humanities research. To support the course, Chris needed a new instance of the AOR viewer setup that would allow his students to study this version of Hamlet. This way, the students could emulate the AOR process to experience research in digital humanities. The AOR technical team provided this new instance, demonstrating how AOR’s technical infrastructure – the technologies that lay underneath the appearance of the books on a webpage – can be adapted for other collections.
The Hamlet prompt book was annotated by the eighteenth-century English actor John Ward, with a greater focus on editing the printed text than Harvey’s more interpretive annotations. On almost every page entire lines are crossed out, words replaced, punctuation added, and more edits that come together to show a reader John Ward’s version of Hamlet.
The current way to represent word substitutions as “errata” did not capture the nuance of the different editing annotations from the Hamlet prompt book. Chris and the technical team decided to represent the various annotations as “substitutions”. These substitutions would be typed, so different edits could be represented, potentially treated differently, and individually searchable. Deletions could be thought of as substituting some letters, words, or lines with nothing. Insertions would basically be blanks substituted with something. This change added one new way to represent annotations in the AOR data model.
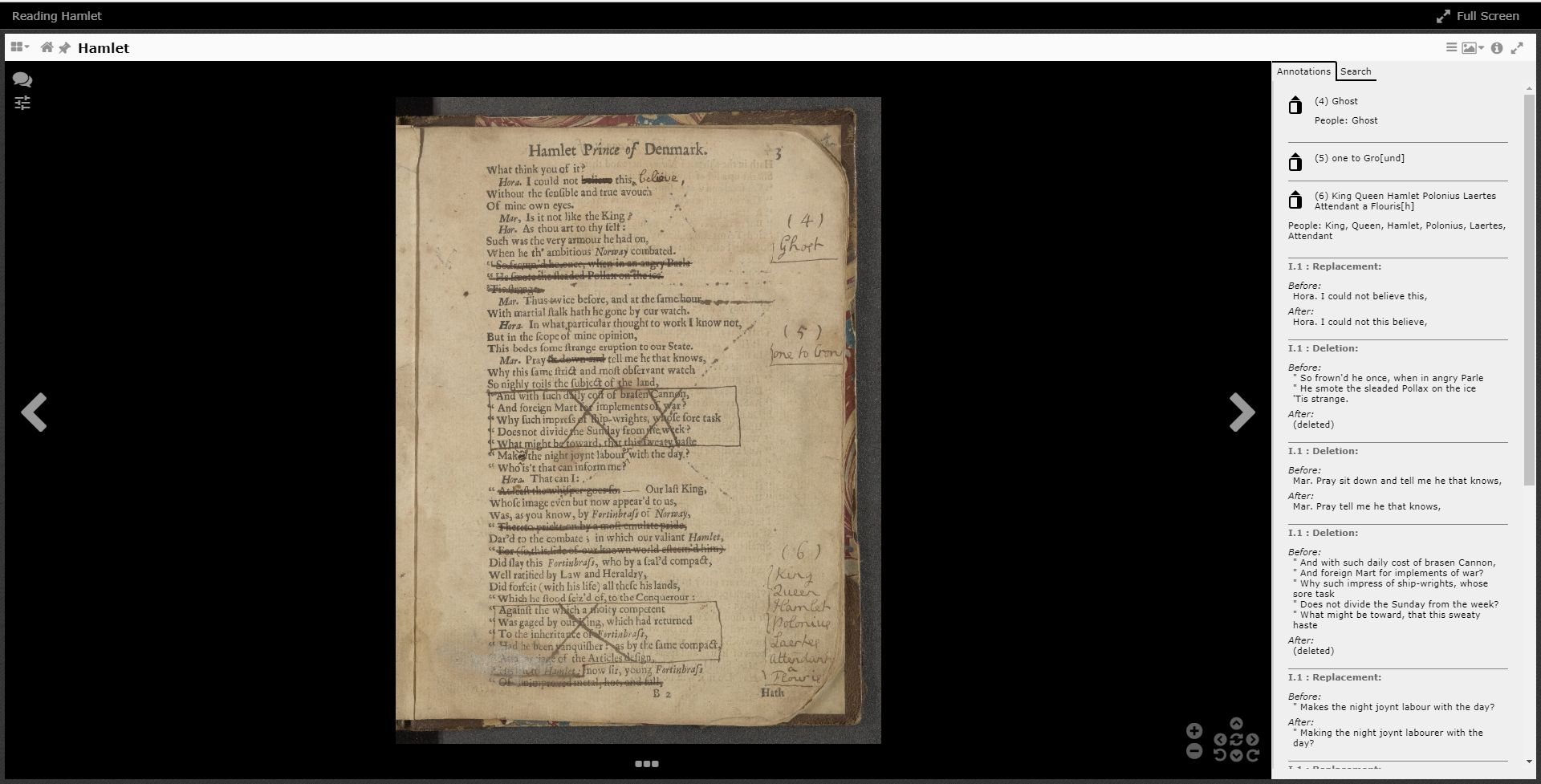
The technical team determined how to handle the new annotations in the viewer. There were two main aspects that needed to be addressed: how these annotations appeared in the annotation side bar and how these annotations were searched in the viewer. When viewing the annotations in the sidebar alongside the page image, we decided what information would be useful to a user and supported a student to identify the annotation in the image. For searching, it was important to separately search for the different types of substitution (which informed the choice of fields and what information to index for each field).
Modifying the technical infrastructure to support this change was fairly straightforward – evidence of its extensibility. Referring to the diagram of the AOR technical infrastructure (see below), this change to some degree affected the Archive, IIIF Presentation Service, and IIIF Search Service. (For more about the technical infrastructure that supports AOR, see the documentation page).
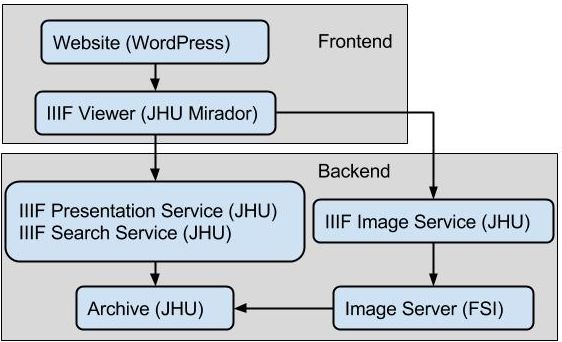
To accommodate these changes, we modified the archive to recognize the new annotations added for the class. Once the new data was recognized in the archive, we treated it the same way we treat the rest of the AOR data. In the IIIF Presentation Service, we defined how the new AOR/Hamlet annotation appears as a IIIF annotation. We used the IIIF Search Service to index the annotation data to make it searchable, which included defining the search fields that a user would pick in the search interface. Once these changes were made to the infrastructure, the Mirador interface was automatically able to display and search the new annotations.
It is important to stress the value of the IIIF standards. Since the AOR viewer understands IIIF data, making changes to the underlying AOR data model does not require modifying the viewer. Instead, we treated the new data by transforming it into a IIIF compliant form. The viewer automatically handled the new data because it is in a well understood format.