I’m Mark Patton, one of two programmers working on the project. The scholars are focused on the research they want to do. John Abrahams and I are focused on the technology required to support that research.
On digital humanities projects like AOR, I always find it helpful to think about the project in terms of data. The data underlying the project must be preserved and then made available in ways that meet the needs of users. The distinction between preserving the content and providing access lets us deal with each problem separately and provides opportunities for sharing technology across projects.
In order to preserve the data, the technical team has to understand it. This requires a detailed description or model of the data and knowing the file formats used for its storage. With that information we can ensure that the integrity of the data is maintained over time. It is essential to do this early on in a project so that workflows that generate data can be automatically checked. Otherwise you will end up with inconsistent data, which is hard to use.
In AoR, the data consists of high-resolution book images, annotations transcribed by scholars, and bibliographic metadata. At a high level, the data is very similar to other projects which involve digital facsimiles of books such as Roman de la Rose Digital Library and the Christine de Pizan Digital Scriptorium. That fact allowed us to extend our existing infrastructure to handle the new type of transcription data from AOR. With our tools in place, importing new data into our archive as it becomes available is a simple mechanical process.
The technical team worked with the scholars to model the transcriptions and come up with a format for storing them that lent itself to a reasonable workflow. Modeling the transcriptions made the scholars think closely about the eventual ways they wished to use them. The resulting transcriptions are very detailed. All sorts of information are recorded: symbols, people, places, orientation, etc. XML is a good fit for this type of data and a format the scholars could manipulate easily. The technical team worked with the scholars to define a DTD and Schema for the transcriptions. The scholars use GitHub to store the XML and manage their workflow. (The technical team is also using GitHub, but to manage the source code!)
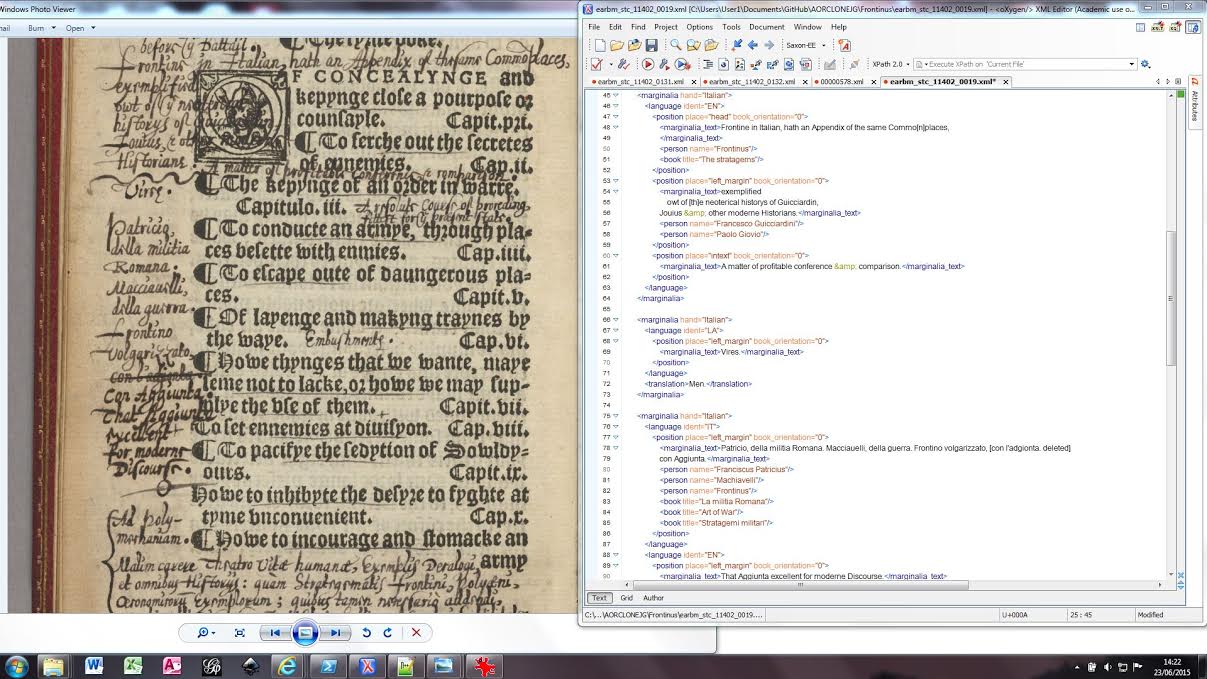
The efforts to model the AOR data and verify their integrity pay off when we can easily write simple tools to produce data for analysis. Below we’ve used a tool that dumps information about annotation types from our AOR data to spreadsheets. Then that data has been imported into Google Spreadsheets and the chart tool used to compare types of annotations across the corpus. One book looks like it must have been underlined in its entirety!