Last Thursday (13.10.2016) the UCL Common Ground provided the stage for our workshop in celebration of AOR going live earlier this autumn (see the previous blogpost). Posters and postcards had been circulating, and with clear results: the afternoon was very well attended.
A panel of AOR-anciens gave four concise, evocative presentations, intermitted with Q&A sessions.
Earle Havens started with a general introduction and spoke of the genesis of AOR, now shrouded in near-legend: the article by Lisa Jardine and Anthony Grafton, ‘Studied for Action: How Gabriel Harvey read his Livy’ (1990), and an inspired meeting between Earle and Anthony in a café in Louvain. The desire to study the history of early modern reading practices in a systematic way gave the project its spark of life.
Three themes connected the presentations: the project’s clear-cut definition of ‘big data’ as ‘too much information’ that, as Matt Symonds explained, is beyond operating with data individually. Much like for Gabriel Harvey and his contemporary readers, the conditio sine qua non for AOR has been to create a framework to deal with such an information overload – to structure the data, as Jaap Geraerts put it in his presentation on the practical aspects of constructing a XML-framework.
Second, the importance of cross-sectional collaboration. As a scholarly resource, it is vital for AOR to build that framework not as ‘words on a page’ but as a mobile, flexible creature that brings together conservational, technological, and intellectual imperatives. AOR exists by the grace of the symbiosis of its bibliographical, technological, and scholarly expertise.
And third, the way in which AOR broadens the research horizon. As became apparent during the Q&A sessions, a resource like this makes new research questions possible: to compare Harvey’s marginalia with Harvey’s own books, for example. Or, as Arnoud Visser from the University of Utrecht suggested in his presentation in which he approached AOR from the viewpoint of an end-user, to start reading between the lines of marginalia and look at what is omitted, not talked about, or implicitly alluded to. Other interesting questions arose during the Q&A, for example asking about the curatorial aspects of assembling the corpus.
When we say workshop, it was only the first leg of the afternoon. The panel discussion was followed by a reception in the Common Ground, during which both the Leffe and the inspiration flowed lavishly. If you want to (re)visit the workshop: a video will be made available in the near future.
In order to celebrate the launch of AOR, our senior programmer Mark Patton has gathered some fun facts about the project:
The AOR project was a lot of fun and also a lot of work. Here are a few facts concerning the work we did and the data we produced.
1) 13 books
2) 5,877 page images taking up 511 GB of storage space
3) 5 transcribers and checkers
4) 2,686 XML transcriptions making up 226,948 lines
5) 4,577 commits by transcribers to GitHub repository holding XML transcriptions
6) 940 commits by programmers to source code GitHub repository
7) 43,324 lines of Java code
8) 3,095 marginalia in L. Domenichi, Facetie (1571) & L. Guicciardini, Detti et Fatti (1571) made up of 36,332 words
9) 26,106 underlines in T. Livius, Romanae historiae principis (1555) of 84,326 words
10) 718 words written in the margins of T. Livius, Romanae historiae principis (1555) page 430v, the most densely annotated page in our corpus (in terms of word count)!
11) The most mentioned book in the marginalia is De Civitate Dei at 23 times.
12) The most mentioned location in the marginalia is Rome at 41 times.
13) The most mentioned person in the marginalia is Julius Caesar at 153 times.
Creating a data set is nice, making it publicly available is even nicer, but it is even nicer still if the data can be “interrogated” in various ways. To make this possible, the development of a robust search facility is necessary. When we started the project, the possibilities for search within IIIF and IIIF-compliant viewers were fairly limited. Developments within the digital world move fast, though, and recently IIIF has released its Content Search API. This search API enables searches within the data associated with the “structural components of the presentation API,” including the manifests (e.g., the books, in our case) and the sequences (e.g., a set of pages of a book). Moreover, digital annotations associated with particular objects will be searchable too. Great as this is, the specificity of the AOR data requires a search widget that is more closely tailored to our data set. Our tech wizards Mark Patton and John Abrahams, both based at the Digital Research and Curation Center at Johns Hopkins University, developed exactly such a widget and integrated it into the AOR viewer. This blog will highlight several of the search functionalities and the way in which specific parts of the AOR data can retrieved by them.
As mentioned in an earlier blog, the AOR viewer offers two kinds of search, a basic and an advanced one. Both the basic and advanced searches return the pages that match the specific query constructed by the user. All the search results are clickable links—that can be opened in the current or a new workspace—which immediately take the user to that page. A basic search is a simple string search that covers all the textual data associated with every type of reader intervention within a particular book or across the complete AOR corpus. For example, a search for “Caesar” returns all the pages on which this name is mentioned in the underscored words of the printed text, marginal notes, and their translations, the printed text that has been associated with particular marks, and so on. The basic search thus constitutes a broad search, a large fishing net, if you like, to scoop up large chunks of data relating to a specific keyword. Basic searches can be made more specific though, for instance by adding quotations marks: a search for Julius Caesar might return instances of Julius and Caesar, while searching for “Julius Caesar” only returns the instances of this name.
The advanced search offers various possibilities. First, a user can focus on a specific type of annotation. One can, for example, look for a specific word in only marginal notes, thus further narrowing down a basic search. Another possibility is to look for specific people, books, and geographical locations mentioned by Harvey in his marginal annotations. Through the advanced search it is possible to construct detailed searches based on an aspect of a particular type of annotation. In the XML transcriptions we have recorded whether Harvey made an annotation with pen or with chalk, enabling searches for all annotations that were made in chalk, for example. We have also tagged the language in which marginal notes or the underscored words in the printed text were written. The user can select a particular language in which a marginal note was written and then search for a key word, or just use the search to retrieve all the instances of marginal notes written in a specific language, useful for those who, for instance, want to focus on Harvey’s annotations in Greek.
Second, the advanced search also allowed for the construction of queries consisting of a combination of search terms, enabling the user to look for specific combinations of key words or types of annotation. As mentioned in a previous post, one can, for instance, search for pages that contain the Mars symbol and marginal notes that mention “Caesar.” Another (fairly random) example would be to search for the pages containing a marginal note that mentions “Caesar” and a marginal note in Greek. Users can add search terms at will, and a virtually endless number of combinations are possible. As a result, the search functionalities open up the AOR data set for the various avenues of inquiry that scholars from different disciplines might have.
A soon-to-be-implemented search functionality is the possibility to sort search results. Currently this functionality exists only on the test server, but it should be available soon. This is what it will look like:
Some wide-ranging searches will yield many results, which can be ordered based on relevance and page number. This will make it easier to manage and navigate the search results and to work with our tool. As the search functionalities are still being developed, partly because of some suggestions made by our users (please continue to let us know what you think!), more updates can be expected. All the search functionalities will eventually be addressed in detail in newer versions of the user documentation (the current version can be found here).
P.S. Just a reminder that last week we launched our second data release, which includes all the transcriptions of the latest addition to the AOR corpus, Tusser’s book on husbandry. The data release and accompanying documentation are available here!
As mentioned earlier, the latest edition to the Harvey corpus is Thomas Tusser’s Fiue hundred pointes of good husbandrie (London, 1580), recently acquired by Princeton University Library. The book is different from the other books in the corpus in terms of its topic —husbandry, the management or political economy of the household— but also in its literary style. For, unlike the other books in the corpus, Tusser’s book is written in verse. This blog will assess whether or not this fact exerted any influence on Harvey’s reading strategies.
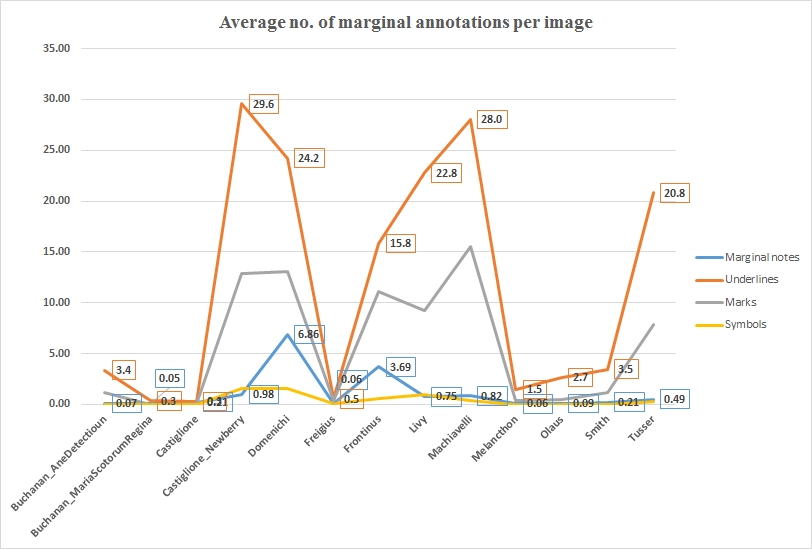
First, let us see whether a fairly straightforward statistical analysis reveals any divergent reading patterns by comparing Tusser’s book to the other books in the corpus. In the following graph I calculated the average number of marginal annotations (divided into the four main types: marginal notes, underline, mark, and symbol) per digital image.
The figures show that Harvey annotated Tusser’s book fairly heavily—it is the sixth most densely annotated book in the corpus. It seems, though, that nothing out of the ordinary was going on. Harvey didn’t use a particular type of annotation more often than in other books, for example. The only thing that caught my eye is the fairly (but not extremely) high average number of underscores. The underline tag captures every word or sequence of words of the printed text that is underlined (as long as a set of words is underscored uninterruptedly), as a result of which the average number of underscores can be “inflated” when a reader underscored a lot of single words. Moreover, although working with the average number of underlines per digital image reduces the possibility of generating misleading statistics as the result of books being different in length (i.e., the number of pages), the different size of the book can still distort the statistics (e.g., a page of the Livy contains more words, and hence possibly more underlines, than a book in octavo format). We therefore should not take the statistics at face value: they can be misleading, as they have been influenced by various factors, including the size of the book and our transcription practices.
In the following graph we break down the number of instances of underscoring in the printed text further and show the average number of words per underline tag.
As the graph shows, Harvey seems to have been remarkably constant in his underscoring practices across the corpus. Whereas the total number of instances he underscored one or more words in the printed text varies greatly per book (from 48 in Buchanan’s Maria regina Scotorum to a whopping 26,088 in Livy’s History of Rome), the average number of words he captured by underscoring part of the printed text actually is quite similar (the only exception being Freigius’s Paratitla). These statistics thus seem to indicate that Harvey did not interact with the printed text of Tusser’s Husbandrie in a different way. Of course we could supplement this analysis with a more thorough linguistic scrutiny of the data, for example, focusing on the classes of words that are underscored. This falls outside the scope of this blog, so I just mention the possibility here.
We should complement our research with a more qualitative analysis of the AOR data set, though. In my opinion, statistics can be extremely useful in laying bare patterns that would have been difficult to discern with the more traditional scholarly methods usually associated with analog research environments. However, digital environments allow us to fruitfully combine quantitative and qualitative analyses. In this particular case, let us have a look at whether the marginal notes contain comments on, for example, the literary style of the book, or whether he frequently used particular symbols, such as Mercury, which Harvey used to mark passages in the printed text about eloquence (and also trickery).
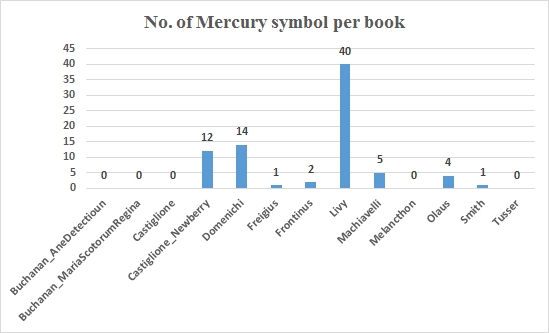
To start with the Mercury symbol, here’s an overview of the appearance of this symbol throughout the AOR corpus.
This path of inquiry clearly is a dead end, for the Mercury symbol does not appear once in Tusser’s Husbandrie. Moving on, neither did a simple search for “verse” yield a lot of results. In Tusser’s Husbandrie, Harvey did not mention this word in his marginal notes and only underscored the word “verse” twice: one time in the index at the end of the book, when referring to “Staints Barnards verses,” and the other time as part of the words “everie verse,” in the preface to the reader. In the other books in our corpus, Harvey did mention the word “verse.” For example, in Domenichi’s Facetei he wrote, “How many verses are there. A 100,” and in Guicciardini’s Fatti et detti, “Hos ergo versiculos feci: tulit alter honores” (I wrote these little verses, and another man received the honors). In Castiglione’s The Book of the Courtier, Harvey underscored “foolish in verses” in a sentence that describes the foolishness of some men in particular activities.
A search for style/stile yields more results. In Tusser’s Husbandrie, next to the header “The description of an enuious and naughtie neighbour,” Harvey wrote: “This, & the next, two notable sonets, aswel for stile, as matter.” (Interestingly, both sonnets are marked with red chalk, possibly another way of engaging with this book.)
When examining Harvey’s other marginal annotations in Tusser’s Husbandrie, it quickly becomes apparent that many of them were written in the upper margin and summarized the content of a page or section, the marginal notes basically functioning as headers. Moreover, the notes comment on the content of the printed text, not on its literary style.
Although we should take into account the facts that the data can be interrogated in many more ways and that our corpus is limited and does not include all books annotated by Harvey (including the book Chaucer’s The woorkes of our antient and lerned English Poet, Geffrey Chaucer, edited by Thomas Speght), on the basis of some limited quantitative and qualitative analyses of Tusser’s Husbandrie, we can tentatively conclude that Harvey was mainly interested in the practical knowledge contained in this book rather than in its literary qualities. In this sense, he did not treat Tusser’s Husbandrie any differently from the other books in our corpus.
Ever since the start of AOR in September 2014, RSA 2016 in Boston had been firmly in the back of our minds and highlighted in our agendas (our PI Earle Havens made it a habit to remind us about this deadline wherever and whenever he could), as this was the time and place where we would launch our viewer and present it to the wider academic community. This was the moment at which more than one and a half years of blood, sweat, and tears had to come to fruition, and in the preceding months the whole team worked hard in order to get the viewer RSA-ready.
The organizers had scheduled our session at the last session (17:30-19:00) on Thursday, March 31, the first day of the conference. AOR was thus the exciting end to a wonderful CELL day, as all the CELL-sponsored panels were planned on this day, starting at 8:30 in the morning and continuing right through the end (some of them annoyingly coinciding with the amazing panels on annotated books organized by Earle, a recurring problem at RSA). All the CELL panels were chaired by our own Matt Symonds, a truly heroic effort for which he deserves great praise!
The CELL panels included a wide and stimulating variety of topics, ranging from new research on the early years of the Bodleian Library, stairs in houses in early modern London, to seeing early modern books as “pestilential clouds.” One panel was devoted to honoring Lisa Jardine and consisted of moving talks by her friends, colleagues, and students (although these distinctions tended to blur for those who were part of Lisa’s familia). Important fact: there were amazing doughnuts as well (in true Lisa style, for whom providing good and plentiful food at academic gatherings of any kind was a matter of personal pride)!
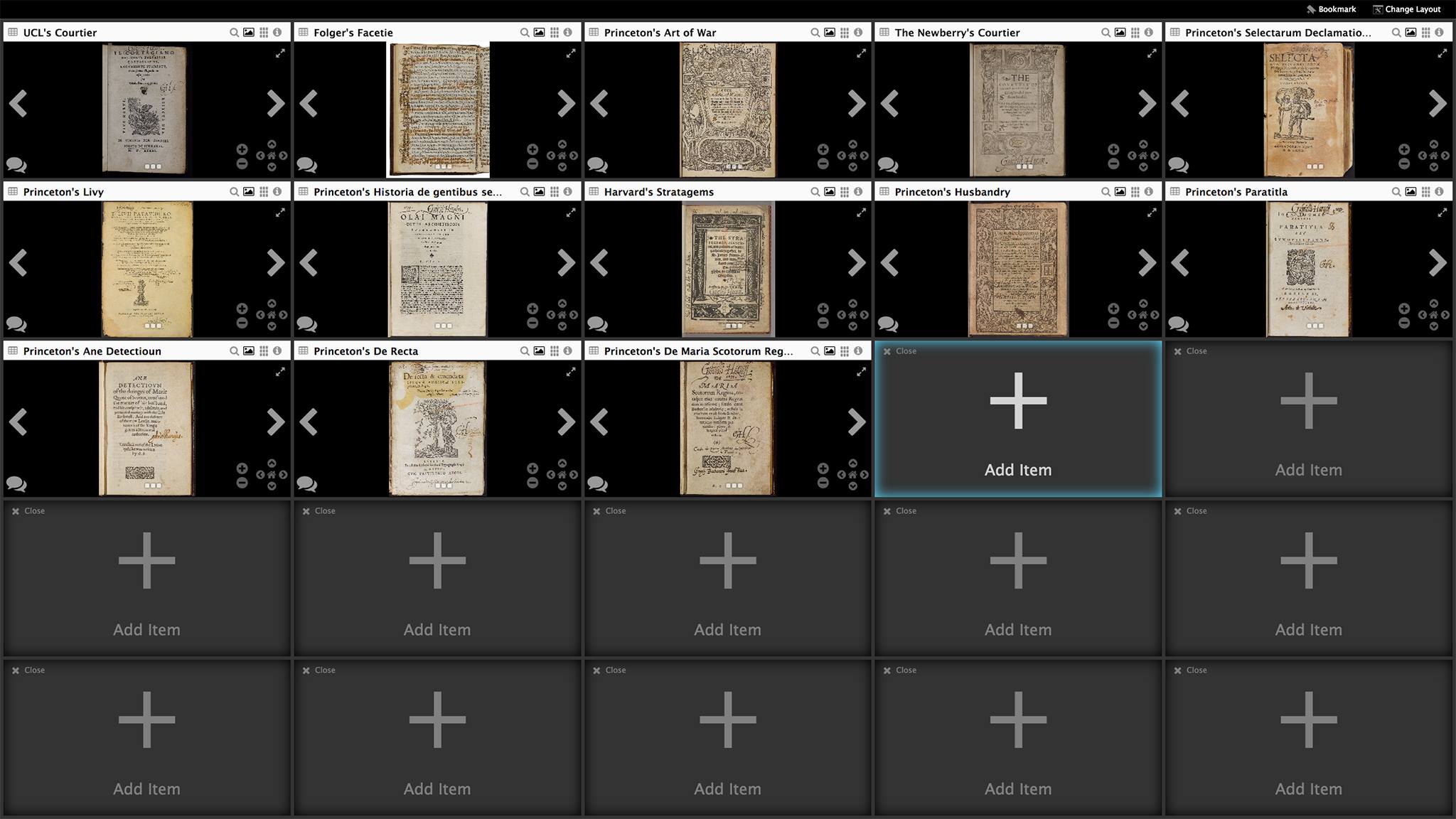
Then, finally, after already quite a long day, the AOR roundtable was to commence. Earle Havens kicked off with an introduction of the project and its relations to the wider historiography of the history of reading. After that, Chris Geekie spoke about some intricacies of Harvey’s annotations and ways in which he dealt with those. Thereafter, it was time for the moment suprême: the launch of our viewer. Matt focused on the image and transcription viewing, showing the bookwheel capacity of our viewer: its ability to open up to 25 (!) workspaces (i.e., the space in the screen where an image and a transcription panel can be opened) next to each other, making possible quick leaps within a book or from one to another book.
I took over by showing and explaining the search functionalities of our viewer, which consist of a basic (string) search and an advanced search that allows users to build complex queries. The advanced search, which is still under development, gives users the possibility to drill deep into the data and discern patterns that are difficult to discover in a traditional analog environment.
And luckily, we got some positive feedback!
Moreover, every single search result is a clickable link, with the user having the opportunity to open the search result in the current or a new workspace, further opening the possibilities to go down the rabbit hole, an expression that seems particularly suited to capturing the possibilities of doing research within the AOR viewer.
After Matt had given a demonstration of a particular search scenario based on his own research, Tony introduced the Winthrop Project to the audience. This project aims to study the library and archive of the Winthrops, an English family that emigrated to New England in the 1630s. This project is closely linked to AOR, but not only because of the shared interest in the history of reading; for the Winthrop library includes various books that were first owned and annotated by John Dee and later by several generations of the Winthrop family, and that will form part of the AOR Phase II corpus. We are very much looking forward to working together and sharing ideas (and technology!) in the coming years.
One last important message:
The AOR viewer is open for Beta testing!! You can find our website at www.bookwheel.org and or viewer by clicking on the bookwheel image at the start page or by directly going to www.bookwheel.org/demo. Please have a go at it and let us know what you think (email earle.havens@jhu.edu or m.symonds@ucl.ac.uk).
In the last blog of 2015 I’ll give a short update on the conferences several of our “archaeologists” recently attended. Reflecting the various strands of the project, the AOR team consists of scholars, computer engineers, and librarians, and as a result a wide variety of conferences are part of our dissemination activities. Last week, on Tuesday December 8, Matt and I went to Ghent to attend a IIIF workshop. IIIF stands for International Image Interoperability Framework, and can be described as an initiative to open up and make accessible the digital image collections hosted at various institutions such as libraries and archives. Whereas most collections are accessible only through their own purposely built viewers, IIIF-complaint viewers are interoperable and can access all collections that are hosted on image servers that support the IIIF presentation and image APIs. The main advantage for scholars is that they won’t have to use and learn to work with different viewers, but instead can use one viewer to access collections scattered across different institutions, enabling exciting comparative research. Institutions, on the other hand, no longer need to invest in creating and maintaining several viewers.
Although we did not present at this workshop, Matt and I attended it because AOR uses a IIIF-complaint viewer called Mirador. We wanted to enhance our understanding of IIIF and to familiarize ourselves with the various projects that make use of IIIF and are currently rolled out in libraries and other institutions hosting image collections. From the perspective of AOR it is particularly interesting to see the ongoing development of IIIF itself: because its APIs are developed for displaying images and providing some related metadata, the functionalities of most IIIF-complaint viewers generally do not move beyond the viewing and browsing of images. The ability to search the digital transcriptions that are displayed next to the corresponding image is of great importance for AOR, and several use cases comprising search have been developed. Although a IIIF search API currently is in development (to be launched around May 2016), we, and by “we” I actually mean our tech wizards Mark and John, are already working on adding some search functionalities to our viewer. In this way, AOR can contribute to the development of IIIF.
A week later, I flew to Washington D.C. to give a presentation with Sayeed Choudhury, Associate Dean for Research Data Management at Johns Hopkins, at the fall meeting of the Coalition for Networked Information (CNI). Interestingly, there were various presentations on IIIF, as well as on projects that relate to data management and preservation within universities, archives, and libraries. In our talk, Sayeed and I focused on the developmental process and workflow of AOR rather than on its outcomes to date. We emphasized the fact that, from the very outset of the project, computer engineers and scholars have been closely working together in creating the project’s infrastructure. This close cooperation is visible in the development of the schema (see my previous posts) and the uses cases, for example, but also in the ongoing discussions about the AOR data model. As Matt has succinctly phrased it: AOR does not rely on a “client-provider” model, where at some point in the project humanists simply ask the techies to build X or Y (which can have disastrous results if at the designing stage critical things have been overlooked). Instead, the development of the AOR infrastructure has been iterative and has evolved out of a continuing dialogue, a deep engagement between scholars and computer engineers, making optimal use of the particular skills and expertise of all team members. This approach, we believe, is one of the strengths of the project, and we shall continue to benefit from it in the future!
This was all for now and, for that matter, for 2015. I’d like to end by wishing all the readers of our blogs happy holidays and a wonderful 2016! See you next year!
Update: Our CNI talk can be viewed online! See: AOR @CNI
Albeit with a heavy heart, due to the loss of Lisa, our director, dear friend, mentor, and source of inspiration, we’ve continuously worked on AOR. We feel it’s important to try to carry on Lisa’s legacy, which can be done partly by making AOR, a project she was so excited about and that got off the ground largely because of her vision and enthusiasm, a great success.
One of the things we’ve done is to update our website, where you now can find a download page. This page contains documentation, such as the Transcriber’s Manual, but also our very first data release, which consists of all the raw data of the project, including the XML transcriptions, the lists of people, books, and geographical locations mentioned by Harvey in his marginal notes, and accompanying documentation. Please do get back to us with any remarks, questions, and suggestions about our data!
For the remainder of this blog, though, I’d like to go back to the topic addressed in the previous blog: namely, how to link marginalia that run across different pages. As mentioned, this practice is particularly challenging for our schema, as it deliberately captures all marginal notes on one page. As a result, both parts of one marginal note are tagged as two separate marginal notes in two separate XML files. In what follows I will explain the way in which we join them together.
But first, an example of a ‘running marginal note’: in his copy of Domenichi’s Facetie, motti, et burle Harvey starts in the left margin on f. 17r with “Hic superat ipsu[m] Ca[e]sarem, et Maronem. Cedant ipse Crispus,” and he continues in the gutter of the preceding page (f. 16v) “Tacitus, Paterculus, Naso huic Eutrapelo. Quicu[m] suo Eunapio, Juliano, Philostrato [-] non modò suis Romanis,” after which the marginal note continues on to the left margin of that page with “singularis est artifex argumentosi, facillimè fluentis, exquisiti styli.”
Here is an image of this marginal note. Take into account that some parts of the text are not visible on the digital image due to the tight binding of the book, which neatly alludes to the limits of digitization, about which Matt wrote an earlier blog
Folgers, Domenichi, f. 16v-f. 17r.
The connection between the two parts of the marginal note is established via two unique IDs which are attributed to both parts. We then use an attribute to refer to the unique ID of the other part. However, we also need to establish the “direction” of a specific part: i.e., is this part the continuation of an earlier part or is it the start of the marginal note? The viewer needs to know this in order to be able to decide whether, in the digital transcription the user will be seeing, the text of a particular part needs to be put in front of or after the text of the other part to which it is linked.
So far, the XML for the parts of this marginal note would be:
We’re still not there yet, as we also need to provide information about the book (in case Harvey continues a marginal note in another book, which can happen, at least in theory, when two books are bound together) as well as about the XML file in which the other part of the marginalia is captured. This information is supplied in two attributes: book_id and marginalia_from/to_transcription (note that this attribute also contains the “direction” of the marginal note). All of which makes:
Admittedly, the names of some attributes are a bit clunky, yet this nevertheless is quite a straightforward solution, even though transcribers have to be careful not to mix up the IDs and the “direction” of the marginal notes (read this as a note to myself, as I’ll be modifying the relevant XML files). For me, this was a particularly interesting challenge to deal with, especially because it again brought together the scholarly and technical strands of this project as it involved discussions with Matt here at the CELL HQ and with Mark and John, the “techies” at DRCC. As a result, this solution is very much the outcome of an incremental process, resembling the development of the XML schema as a whole. The issue of linking marginalia, as it touches upon various aspects of this project, again highlights why DH projects, and AOR in particular, are so fascinating.
For as assiduous an annotator as Gabriel Harvey, few things would have been as annoying as running out of white space. Indeed, he often used every inch of white space available, as this image shows:
Domenichi; f. 187v – f. 188r
It also becomes clear that, even with sufficient space, Harvey still needed to take the layout of the printed text into account, as a result of which his marginal notes snake around and sometimes through it.
The challenges posed by the layout of the text and the size of the page made it necessary for Harvey, who could be fairly long-winded, to link parts of his extensive marginal notes to each other. Often he employed marks or symbols to establish such a link, while he also repeated the first word of the subsequent part of the marginal annotation, thereby imitating a manuscript convention that had also found its way to printed books. By including such signifiers, Harvey provided his readers with a guide as to how his marginal notes should be read.
Domenichi, f. 13v – f. 14r
As this image shows, Harvey enthusiastically started writing in the right margin of the page (f. 14r), but once he had written the word “aut” he found himself out of space. Therefore, he wrote an equal sign and continued the marginal note in the printed text, also starting it with an equal sign to signify the link between the two parts. Harvey still hadn’t finished though, and ran out of space again! He repeated the last word of this part of the marginal note, “Extentu,” in the left margin, where he cheerfully carried on writing. Yet the page continued to challenge him, and he found himself without space yet again. The marginal note ends with a column, a signifier that this marginal note still wasn’t finished. Harvey continued writing in the gutter of the preceding page (f. 13v), showing that he considered the whole opining, not just a side of a folio, as the page.
Now things are starting to get interesting from the point of view of our schema as well, as we’ve decided that the transcriptions capture all the reader’s interventions on a single page but we now come face-to-face with a marginal note that deftly defies the structure of our schema. This poses a challenge we need to solve, for it happens more than once. In another blog post, which is due to appear in the near future, I’ll discuss the solution we came up with.
Unbelievably, I’m coming to the end of my term on the Archaeology of Reading Project, time really has flown by! Whether through writing up transcriptions or checking them, I’ve been very lucky in having encountered quite a few of the books from the corpus we are using, including the Livy, Olaus, Domenichi, and Melancthon texts.
One of the things I have found the most remarkable is the enormous variability in Harvey’s method of annotation. While texts like Olaus’s Historia de Gentibus Septentrionalibus are lightly annotated, as has been discussed in previous blog posts here, Harvey demonstrates a profound aversion to blank space in his use of the Domenichi volume. There is some consistency between texts insofar as he uses a fairly fixed set of symbols with which to flag certain types of content, but on the whole each book tends to evidence a distinct style of annotation. The Newberry library’s copy of The Book of the Courtier was fairly straightforward to transcribe in its lack of fiddly in-text marks; Olaus’s Historia, on the other hand, was a very different story, with a profusion of tiny plus signs all over the page.
As I reach the end of my involvement in the project, Harvey’s use of symbols has perhaps become quite indicative of what I have found most fascinating about the work so far. While many of the symbols are quite comprehensible, this one has been a long-standing source of frustration to the CELL team:
I (and many of my colleagues!) am simply desperate to know what it means, but it has remained elusive to us so far. I will certainly make no complaints if anyone has any exciting suggestions as to what it might be, but it also serves as a reminder that marginalia are not a transparent window into the mind of readers of the past, and that they always require an act of interpretation to be used in modern scholarship.
I am incredibly excited over the prospect of seeing some of Harvey’s more baffling notes, scribbles, and symbols situated in the wider context of his marginal annotations as the completed corpus of transcriptions becomes available. However, I do not remain hopeful of a concrete explanation for the motivation of marginal annotations like this one in the Domenichi:
I am certainly very sad to see the end of my time working with such a wonderful group of people, and I cannot wait to see what the AOR team does next!
Transcribing all of Harvey’s annotations is not always an easy—let alone enjoyable—task, mainly because of his obsession for detail, as a result of which some transcriptions seem to be never-ending—or at least it surely feels like that. However, precisely because of this level of detail, when transcribing one sometimes encounters particular annotations that are likely to be overlooked when studying Harvey’s annotations, especially because we, almost reflexively, tend to direct our gaze to the marginal notes, which are seen as (and often prove to be) the richest and juiciest source of information.
One of these particular annotations that attracted my attention are the words “pro se quisque,” which Harvey underlined in his copy of Livy’s history of Rome. I was intrigued by this, not so much because of the meaning of the words (“everyone for himself”), but because of the fact that Harvey underlined it with dots instead of a more or less straight line. This prompted me to add another variable to the method attribute of the underline tag, further expanding the search options.
Livy, Ab urbe condita, [sig. A1r]
When continuing my transcription of Livy’s history of Rome, I was surprised to see that underscored the words “pro se quisque” more often; we have just finished transcribing Livy’s history in its entirety (!!), and it turns out that he underlined this phrase twenty-five times. Most often he would just underline these three words (fifteen times), whereas ten times he underscored them as part of a slightly larger set of words. Underscoring these words by using dots, which initially attracted my attention, proved to be quite uncommon (only five times), as he normally preferred to use lines.
Livy, Ab urbe condita, 454.
Interestingly, the words “pro se quisque” are not just underlined in the printed text, but also appear in five marginal notes. In the first of these notes, Harvey wrote: “Everyone [strove] for himself, with no king at this time. The people favoured their power, the Senate its authority. The basis was of the people. Yet Romulus was the master and the common people were the slaves, just like here” (p. 9).
The lack of strong leadership, and its negative repercussions for the Roman state, are echoed in other marginal notes as well: “For a nation that was the richest, most active as well as the shrewdest in the world it was not difficult to command kings and dominate the world. How many kings there are in one popularist city? Each one [strives] for himself.” Elsewhere he wrote: “The Roman offices served the use of the republic, not the grandeur of individual persons. Every one for himself, and those who cannot be Scipios abroad, want to be Petiliuses at home. And they have the nerve to taunt those by quibbling who they do not dare to rival by deserving well” (p. 689); and “A skillful move in a difficult situation. Everyone [strives] for himself, [see] above, below. Shyness in holding power and dealing with matters is for a boy, not a man” (p. 76).
It is also interesting that the underscoring of the words “pro se quisque” and the marginal notes that contain this phrase never coincide (i.e., appear on the same page): it was a running theme, a topic in which Harvey was interested and which he addressed throughout the book—sometimes in the form of underlining, sometimes in the shape of a marginal note. It certainly was always on his mind, for after “having thoroughly read the above two books . . . I have come to understand in the end, that it was pivotal to distinguish most clearly the curiae, assemblies, laws, magistrates, customs, even the rewards and punishments according to the type of Republic, and its form, each individually, and that all should be fitted in entirely, in the most suitable way.”
Harvey concluded that this had not always been the case throughout Roman history, “so that they [the Romans] were more prudent for themselves than for the Republic. For look wherever you wish in Roman history: everyone [strives] more for himself [my italics], than for the Republic; the devotion to the household is greater, than that to the fatherland; there are more rich and respected housekeepers than fair and wise politicians” (p. 63).
Livy, Ab urbe condita, 63.
The lengthy note continues on the next page, and Harvey argued that if the Romans had tailored their laws and political offices more closely to the nature of the Republic, this would have contributed to the well-being and stability of the state. This certainly was an important insight, and as the marginal note continued, Harvey wrote: “And for this consideration Philip Sidney, the prominent courtier, thanked me generously, and he openly acknowledged that he had never read anything of such importance either in historical or political works. That he had observed far and wide Romans who were too much senatorial in a popularist Republic and ones who were too much popularist in a Senatorial Republic, ones who were not royalist enough in a monarchy, citizens rather than subjects. And that he had no doubts whatsoever that if they had adapted themselves to the constitution of the State, that they would have come out as the strongest nation, the most successful and powerful people in the world. And this was our most important observation about these three books. . .” (p. 64).
Here the full meaning Harvey attributed to the phrase ‘pro se quisque’ is disclosed: it denotes not only people striving for their own interests at the expense of the larger, public good, but also people acting contrary to the constitution of the Republic, disturbing its balance and harmony and creating internal turmoil.
Here the full meaning Harvey attributed to the phrase “pro se quisque” is disclosed: it denotes not only people striving for their own interests at the expense of the larger, public good, but also people acting contrary to the constitution of the Republic, disturbing its balance and harmony and creating internal turmoil. Interestingly, in only two of the other eleven books in our corpus did Harvey either mention or underscore the words “pro se quisque.” He did this in two marginal notes, one in Domenichi’s Facetie (**2[r]) and one in Guicciardini’s Detti et fatti (p. 48). In both cases, the context in which this phrase appears is different from the context (and content) of the marginal notes in Livy’s book.
Although more research could be done—e.g., Did he underline all instances of “pro se quisque” in the printed text? What was the context in which this phrase was used in the printed text? Why did he use various forms of underlining? Are other marks used to highlight this phrase?—this example neatly shows the links between various forms of readers’ interventions, in this case underlining and marginal notes. For a transcriber, that’s probably the most valuable outcome of this small case study: it shows the benefit of having tagged all of Harvey’s interventions, which, if only for a moment, lightens the burden of what sometimes can be an arduous task.