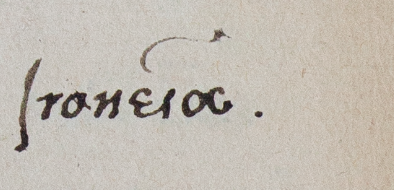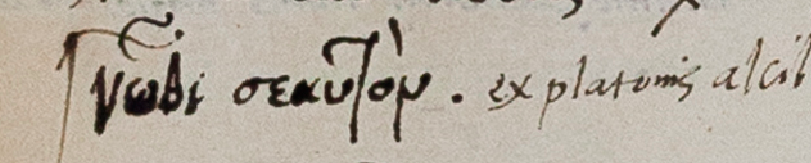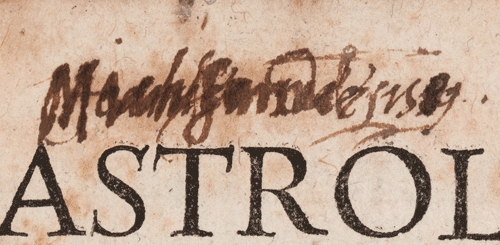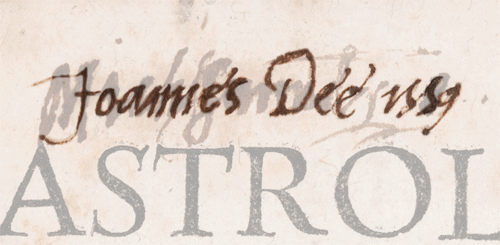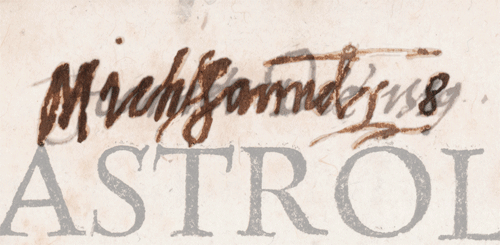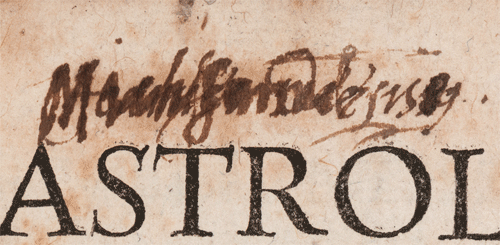Happy New Year from the AOR team! In order to start 2019 and the last month of AOR with a bang, here’s the blog written by our research assistant and newly-minted doctor Juan Avecedo!
I have spent some weeks transcribing Dee’s Greek marginalia in the AOR corpus, which includes mostly topical notes, a few citations from related Greek works, and occasionally also a reference to a significant Greek associated concept. So, apart from the citations, which are rare and can be a few lines long, his Greek notes are very succinct and to the point. It is known that in other works, as in his diaries for instance, Dee used Greek for reserve’s sake, like for private notes, so much so that he referred to himself with the Greek acronym Δ. But in the AOR corpus, his Greek notes are mostly limited to technical terms in rhetoric, astronomy, geometry, astrology and other fields. This is why what I have found more interesting in this short acquaintance is the privileged glimpse into the intimate relation between a scholar like Dee and the Greek language.
Euclid, Elementorum, p. 12.
Rabelais famously spoke of Greek being transmitted from hand to hand over the centuries like a secret knowledge, and with Dee one is struck by how the use of Greek is effectively a persistent evocation or rather, properly, an invocation of the original sources of knowledge, and thus a permanent reminder. I would suggest that in his marginalia the use of Greek is a reminder in two complementary ways: a very practical one, namely the recalling of technical terms and expressions; and another way, more philosophical and more direct, whereby we are reminded of that ‘hand to hand’ continuity, of the ever present, ever available treasury of Greek literature and knowledge.
Quintilian, Institutio Oratoriarum, 89.
Another interesting question that leaps from the annotated pages is the extent of Dee’s proficiency in Greek. It is known that upon the foundation of Trinity College, Cambridge, in 1546, he was appointed under-reader of Greek, so he must have obviously been adept at teaching Greek. He possessed a number of Greek books which he marked and annotated copiously, so it is obvious that he was used to reading it too. What his Greek annotations reveal is, I believe, the insouciance of the true expert. His annotations are for the most part fully accented, which is no mean accomplishment in Classical Greek, but sometimes they are only partly or wrongly accented, or even mixing Latin and Greek letters. What this tells us, especially when contrasted with lengthier passages copied verbatim without any mistake, is that the majority of his Greek notes were made impromptu, without a model, and this would not be the case if the writing of Greek had not been a familiar activity to him. It is hard to tell how he would have compared with his contemporaries in this regard, but against our current standards, and upon the scrutiny involved in these transcriptions, I feel one can confidently say that Dee was an accomplished Hellenist in every way.
We have arrived in the last months of AOR, which is scheduled to come to an end in late January. This means that we are busy with getting the next version of our digital research environment ready. Part of the remaining work is very exciting and comprises the creation of a set of contextual documents on John Dee, his books that are in the AOR corpus, and his library. To that end, a humanities meeting was recently held at Princeton’s Institute of Advanced Studies (see Neil’s blog for more information). Necessary but unfortunately somewhat less exciting is the work that takes place in the trenches: checking transcriptions, hunting down bugs, and testing the viewer. This blog post addresses a problem which has haunted us over the course of AOR and which we had to face head on last month.
The problem is a rather mundane one: displaying the correct page numbers of a particular book in the AOR viewer. Getting this right proved to be labour intensive, while the problem itself shows the tension between the ways in which a (digitized) book as an object is viewed from distinct humanistic and technical perspectives. The problem emerged due to a combination of the particular technical infrastructure inherited from earlier projects conducted at Johns Hopkins University (JHU) and our transcription policy. Based on earlier work on the Roman de la Rose and the Christine de Pisan projects, the digital images that are ingested into the JHU archive are labelled according to the sequence of manuscript, starting with 1r, followed by 1v, and so forth. This folio numbering system both reflects the objects on which these projects focused, medieval manuscripts, as well as the conceptualization of objects within IIIF viewers as a sequence of images. However, anyone vaguely acquainted with early modern imprints will now that the page number system of these objects in general is much more complex because of the combination of page numbers and signatures, with some books having separate sequences of page numbers and/or signatures for individual sections.
As a result of the internal system of attributing page (i.e. folio) numbers, a mismatch between the page numbers visible on the digital images and the page numbers displayed in the bottom of the viewer emerged, as shown on the image below.
One way to overcome this hurdle was to include information about the page number and signature in the XML transcriptions generated for the project and to display this information in the viewer. We managed to get this working in the new version of the viewer – which currently is under construction and not yet publicly available – but quickly realised that this problem continued to persist in a number of cases. This was caused by our decision not to create XML files of all digital images, but only of those that contain one or more reader interventions, that is, any visible interaction of a reader with that page. Since at least around half of the pages in the books which are included in the AOR corpora are not annotated, XML files for these pages do not exist. As a result, for the pages which do not have an XML file associated with them, the viewer returns to its internal numbering system, creating an extremely awkward combination of page numbers and/or signatures and folio numbers (see below).
Several possible solutions existed, including the creation of a XML transcription for every digital image in the AOR corpora. This would mean having to create several thousand XML transcription which, although the transcriptions themselves would be small, would take in inordinate amount of time. The other, more feasible option was to create spreadsheets for every book in the AOR corpora which comprise information about the file name of the digital image and the information about page numbers and/or signatures (in the absence of the former) contained in the XML transcriptions. Luckily the junior programmer working on AOR, John Abrahams, was able to generate these spreadsheets, which meant that I ‘only’ had to enter manually the information regarding the page numbers of the digital images which do not have a transcription associated to them.
Nevertheless, I still had to go through 35 spreadsheets, check the information provided in them, and add/amend data where necessary. This process was further complicated by the mismatch between the file names of the images to which we refer in our transcriptions and the file names that are used internally in the JHU archive. These internal file names, created during the process of ingesting the digital images into the JHU archives, were provided in the spreadsheets. Based on the data in the transcriptions, I had to match the two sets of file names and then add the correct information to the spreadsheets. While being motivated by the thought that finishing this work would constitute an important step towards beatification, and spurred on by listening to football shows and a healthy dose of death metal, I did manage to populate all the spreadsheets. Although the work itself was everything but interesting, the final result is all the more pleasing. The information provided in the new version of the AOR viewer now matches the page numbers and/or signatures of the early modern imprints. Apart from avoiding confusion, this makes navigating these annotated books and doing research in the AOR digital environment much easier. Moreover, during the process of going through the spreadsheets, I encountered a couple of bugs (e.g. transcriptions being associated with the wrong images), constituting an additional fruit of this work. Apart from being a heroic story of sacrifice, perseverance, and the divine combination of football and metal, this blog shows the extent to which the spade work, done by both by computer engineers and humanists, forms the rock upon which this digital resource is built.
At the most recent conference of the Renaissance Society of America (RSA) in New Orleans, I planned to speak about the difficulties in writing a more general history of historical reading practices and offer several possible solutions. More specifically, I wanted to explore various strategies which can be employed in order to examine similarities and differences in the reading practices of Gabriel Harvey and John Dee. Sadly, though, a winter storm prevented me from leaving Princeton and ultimately from giving my paper as I only arrived in New Orleans on Friday afternoon (hence missing out on most of the conference). Although my paper was unlikely to revolutionize the field, some of the issues I address are relevant to those working on the history of reading. I therefore would like to make use this space to briefly discuss one particularly vexing problem, namely the difficulty of incorporating topical marginal notes in our analysis.
According to Bill Sherman, a ‘topical note’ are those marginal notes which acted ‘as a concise key to the topic of a passage’ (Sherman, Dee, 81). In general these notes consist of a just few words, often copied from the printed text, which indicate the main topic of a section. It is not that these topic notes completely escape the possibility of scholarly analysis: at their very core they show the particular intellectual interests of a reader. When having the advantage of working with a known reader, such as Dee and Harvey, knowledge of the historical context is of invaluable help when trying to make sense of such annotations. As Sherman remarked, ‘Dee’s notes in these passages [in some medieval books] are rarely interesting in themselves…but their value lies in the fact that he consistently drew attention to the material that would inform his own historical and political discourses’ (Sherman, Dee, 91).
At the same time, even when equipped with (detailed) biographical information about a reader, the lack of interpretation on the part of the reader in turn renders topical notes difficult to interpret for scholars. Hence our inclination to focus on those marginal notes which are more verbose and informative in nature. However, such marginal notes represent only a small minority of the annotations that decorate the pages of most early modern books. Due to our focus on the relatively small number of interpretative notes, our research tends to be rather impressionistic in nature. But in general, topical notes abound: they litter the pages of the books owned by John Dee, while even a substantial number of annotations made by Gabriel Harvey, unusually verbose when annotating his books, are of the topical kind.
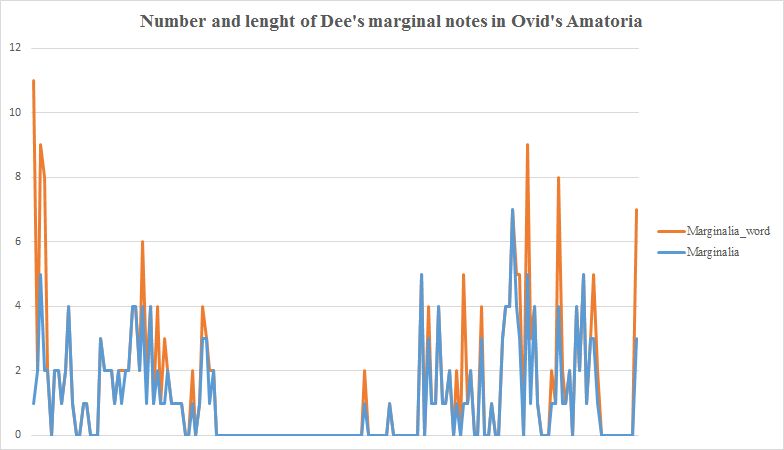
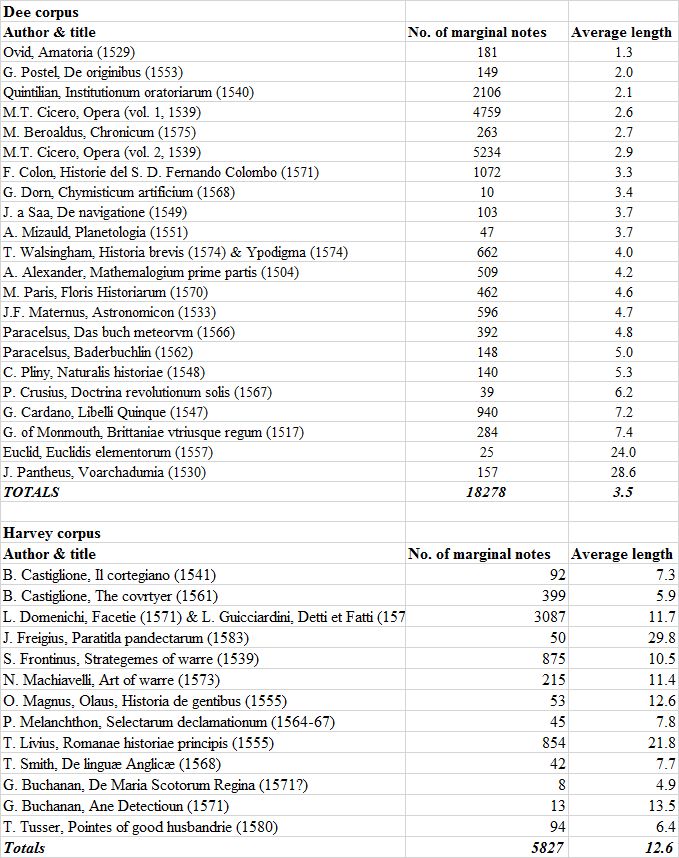
Data-driven approaches can be used to show the proliferation of topical notes and might offer a solution to overcome, at least partly, their limitations. A particularly revealing case is Dee’s copy of Ovid’s Ars Amatoria (Paris, 1529). Dee only annotated this book sparsely: he scribbled 181 marginal notes in the margins while he underlined approximately 4000 words of the printed text. Moreover, the average length of these marginal notes was 1.3 words, meaning that the majority of these notes just consisted of one word.
This is very little, even when compared to other books annotated by Dee and Harvey (bear in mind that the transcription work is ongoing and the figures in this overview are based on the statistics generated in late March 2018).
Some books clearly stand out. Dee’s copy of Euclid’s Elementorum, for example, only contained 25 annotations, but with an average length of almost 24 words (23.96). This average is greatly inflated by the appearance of a couple of lengthy marginal notes at the start of the book. The numbers relating to Dee’s copy of the Pantheus’ Voarchadumia are skewed as well: Dee interleaved this book with blank pages onto which he copied the text another tract by Pantheus, the Ars Metallicae. Because these interventions are treated as marginal annotations, the average number of words is greatly inflated. Harvey’s copy of Livy’s History of Rome, boasts a similar average (21.8 words), but based on an astonishing number of 854 annotations. Although massive annotations, such as one which consists of a staggering 718 words, helps to increase the average, the number of annotations which consists of one word are extremely limited: just 17 out of 854 annotations (almost 2%).
(Topical notes in Livy’s Ab urbe condita, p. 27, and Frontinus’ Strategemes, Gii).
In general, Harvey’s annotations were lengthier than those of Dee, as visible in the table above: Harvey’s average of 12.6 words against Dee’s average of 3.5 words.
Let’s return to the example we started with, Dee’s annotations in Ovid’s Ars Amatoria, and have look at the content of these short marginal annotations. When creating a list of the words and the frequency with which they appear, the results are everything but surprising: number one on the list is the word *drumroll* amor (or its declensions), which is mentioned 31 times. In the vast majority of cases, the marginal note solely comprises the word ‘Amor’. What to do with these marginal notes? Close reading is one possibility: which passages did Dee mark with this word and, just as significantly, which passages were not indicated by Dee in this manner. Such an analysis can be expanded by including other books which contain marginal annotations with the word ‘amor’. Such a ‘thematic’ search returns several hits for marginal notes in Cicero’s Opera and Quintilian’s Instititionum and can reveal a reader’s interest in a particular topic across his or her library.
Another, data-driven approach, would be to employ statistical analysis. This is a strand of AOR that we started to develop near the end of the first phase of the project (2014-6) which focused on Gabriel Harvey. Our approach is based on the creation of concept groups, consisting of words which are related to a specific topic, including war, kingship, eloquence, books, action, etc, and which appeared with a certain frequency in Harvey’s marginal annotations. After that we, and by we I mean professional statisticians, calculated whether or not there existed statistically significant correlations between concept groups. That is to say, the extent to which words which are part of one particular concept group appear in conjunction with words that are part of another. In this way, we can discern whether particular topics of interests were related to one another. As such, we are primarily interested in the intellectual patterns that appear in the marginal notes, not in the numbers generated by the statistical analysis themselves.
Although at present it is impossible to subject Dee’s annotations to such an analysis, simply because the transcription work is ongoing, we will be able to do so in a couple of months. By means of thematic searches and data-driven approaches such as statistical analysis, it might be possible to include some topical marginal notes into our scholarly investigations. Such data-driven approaches do not necessarily yield information about individual marginal notes: one-word notes, for example, cannot reveal a correlation between concept groups. However, topical notes are included in concept groups and hence figure in a larger thematic analysis.
We might be even able to expand the current statistical analysis: what happens when we start to study the correlation between books, people, and concept groups? Another possibility is to check the names of the people mentioned in marginal notes against the index of a particular book. Which people were and were not singled out by our readers? I mention these possibilities in order to make clear that there are strategies for the inclusion of topical notes in our analysis. Invariably, such strategies are time-consuming and will require a lot of work from the scholar. However, they might enable us to include a larger number of marginalia in our analysis and to get a more rounded understanding of historical reading practices and strategies.
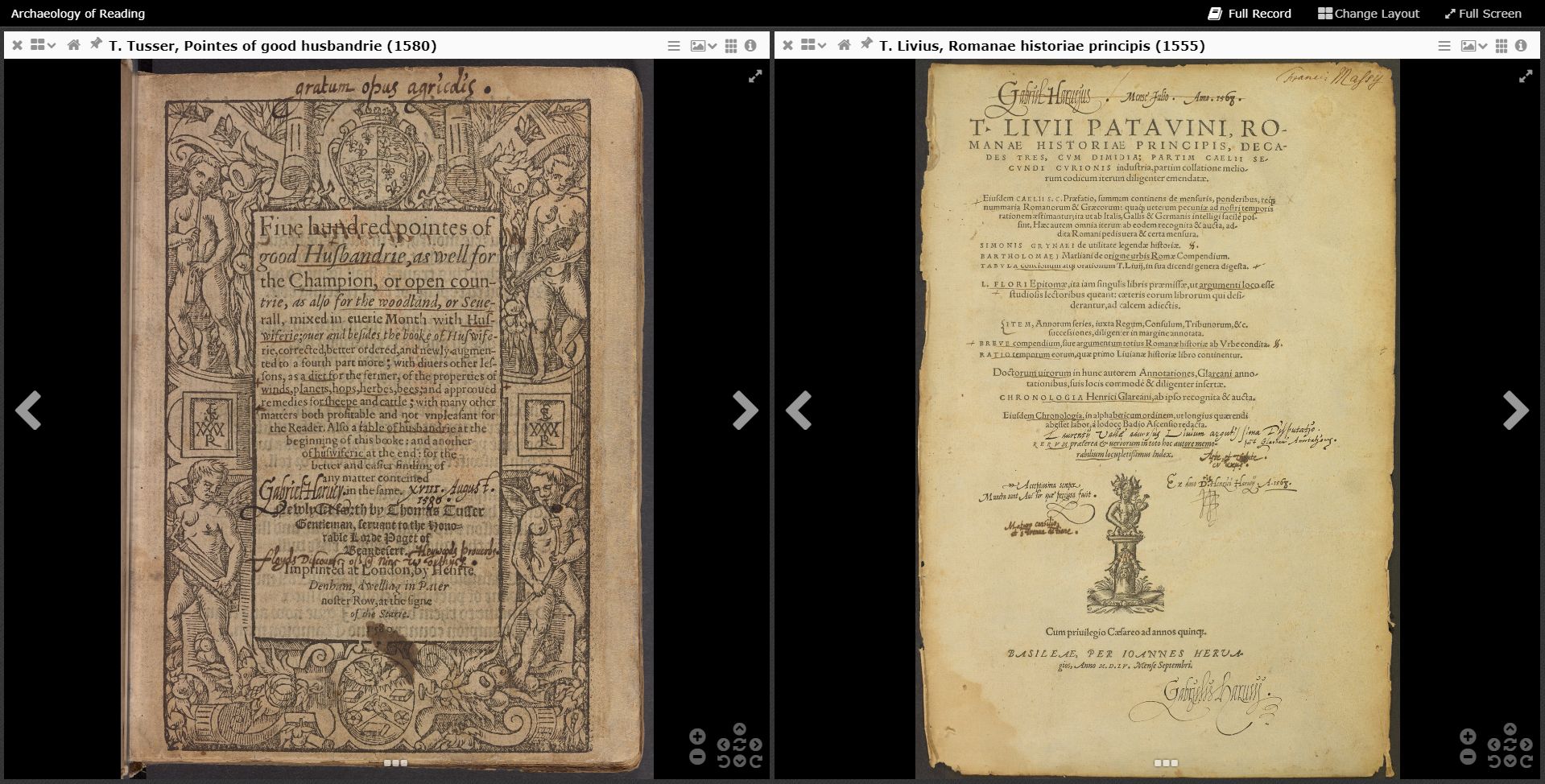
In an earlier blog, Matt Symonds discussed some losses which are inevitably part of the process of digitization. The material aspects of books in particular – their size, weight, feel and, indeed, smell – are difficult or impossible to convey on a screen. Consider, for example, the title pages of Livy’s History of Rome and Tusser’s Husbandry as displayed in the AOR viewer. The size of the images is exactly the same, obscuring the actual differences in format (the copy of Livy’s History owned by Gabriel Harvey is a hefty folio, whereas Tusser’s Husbandry is a quarto).
In spite of the loss of some of the physical qualities of a book when transferring it to a digital environment, in most cases the pros of digitization still outweigh the cons. Above all, the increased and ready access to books (as well as to archival documents) is a major stimulus to scholarship as it overcomes all kinds of financial, spatial, and institutional hurdles.
When doing research on Catholic marriage practices in the seventeenth-century Dutch Republic, for example, a manuscript letter made mention of a tract written by the priest Joannes Stalenus. A quick search on google returned a digital version of Joannes Stalenus’ Dissertatio Theologo-Politica hoc tempore discvssv & scitv necessaria […] (Cologne, 1677), a book recently digitized by Google (see here). Due to the existence of this digital copy, I did not have to hunt down the book in research libraries in the UK or abroad, but could directly access it. The online availability of a digitized copy of this book was so useful because I was primarily interested in the contents of this book, and not in the physical or other aspects that are specific to this copy. In other words, a digital version of any copy would have sufficed for my purposes (as long as the quality of the digital copy is up to scratch).
As a scholar of historical reading practices, however, I’m very much interested in particular copies of books, namely those which contain reader interventions, physical remnants and traces of the ways in which people used their books in early modern Europe. This morning I wanted to call up a particularly densely annotated copy of Cicero’s Librorum philosophicorum uolumen primum […] (Strasbourg, 1541) which is part of the collections of the British Library (BL) (shelf mark 525.c.1,2.). In the spring of 2016 I stumbled upon this book when searching the holdings of the BL for books annotated by the Elizabethan polymath John Dee, but soon realized that it was not Dee who annotated this book (to my great relief, I have to admit, since transcribing this book is a gigantuous task). This is what some of the pages of the book look like:
To my surprise, I was not able to order this book through the online catalogue of the BL (although I was later assured by a librarian that this should still be possible), but was referred to its digital version – the book has recently been digitized by Google. Duly I opened the digital version of the second volume, but my initial enthusiasm vanished as a saw how sloppy a job had been done.
A number of marginal annotations which decorate this particular copy have been trimmed, instantaneously rendering this book useless for those of us who want to examine the annotations. Compare this image, for example, with the image above (a picture which I took myself some time ago).
Based on a quick inspection of the digital copy, it seems that the marginal notes in the gutter have been completely captured, whereas the marginal annotations in the outer margins often have been trimmed, as can be gleaned from the following image:
Compare this with the picture of the same opening I took:
In general, the annotations in the gutter are most difficult to capture, in particular when a book is tightly bound. That does not seem to have been the problem here, so it is a mystery why so many annotations have been trimmed. Perhaps this has something to do with the particular process of digitization employed by Google, is simply the result of a lack of interest or knowledge, or is caused by the lasting influence of the idea that only the printed text really matters. It is, after all, not so long ago that collectors and booksellers preferred to have ‘clean’ instead of ‘dirty’ books and resorted to various methods in order to restore their books to their (presumed) original and pristine state (see William H. Sherman, Used books, Ch. 8). Whatever may have caused these flaws, this particular digital version is nothing more than a pale and incomplete representation of the original object. It still is useful, but only to a very limited extent. The process of digitization always involves some loss, but digitization done badly hampers rather than furthers scholarship.
At the very beginning of the first phase of AOR (2014-2016), I started working on what would become the Transcriber’s Manual. Initially this document was intended to provide the research assistants with an overview of all the reader’s interventions thus far encountered and with guidelines for capturing these interventions in XML. Back then, the AOR XML schema still was under construction and subjected to frequent modifications. As a result, the Transcriber’s Manual became more than just a manual: it also turned into some sort of a log book in which we documented the decisions made in relation to the development of the XML schema. Therefore the Transcriber’s Manual not only is a useful reference work for those who are interested in the particular ways in which the AOR transcriptions are constructed, but also contains the rationale for our specific approach.
As AOR progressed and new books were digitized and transcribed, the Transcriber’s Manual steadily grew in size, making various internal reorganizations necessary. Due to the large number of high-res images, the document became so unwieldy that my old laptop would invariably crash when trying to amend and save it. Happily, the arrival of a new computer swiftly put an end to these problems. Since the start of AOR2, the Transcriber’s Manual has expanded even further. Moreover, due to the inclusion of several new reader’s interventions, we had to amend the ‘old’ AOR XML schema and created a new schema for phase 2 (2016-2018). Because we had always intended to design a fairly lightweight and flexible XML schema, we managed to include these new reader’s interventions without having to radically alter the structural features of the schema.
In order to document the evolution from AOR1 to AOR2, we decided to create a new version of the Transcriber’s Manual. The AOR2 Transcriber’s Manual still contains most of the content of the old Manual, but lots of new information based on the AOR2 corpus of books annotated by John Dee has been included, too. The dual nature of the Transcriber’s Manual is kept intact: just like its previous iteration the latest version of the Manual contains guidelines for the research assistants and well as an explanation of the decisions we made. Recently, in addition to the AOR1 Transcriber’s Manual, the AOR2 Transcriber’s Manual has been made available on the AOR site. Hopefully these documents are of any use to those who wish to gain a more fuller understanding of our working practices or who would like to embark on a project similar to AOR themselves.
P.S. Last but not least: the AOR2 Transcriber’s Manual contains sections with overviews of unknown/unidentified marks and symbols. Any input would be greatly appreciated!!
I have always been a big fan of the Dutch expression ‘het nuttige met het aangename verenigen’, that is, to combine or unite the useful with the pleasant (in Dutch – a superior and more elegant language 😉 – it sounds far less clunky). Recently several members of the AOR team spent a perfect week in Poland, and we managed to achieve just that! The week started with a two-day colloquium, titled ‘Libraries, Scholarship, & Science at the Crossroads, from Nicholas Copernicus to John Dee, 1490-1610’. A large variety of topics were addressed in the papers presented at this conference, ranging from the (alchemical) writings of Edward Kelly, astronomical works heavily annotated by Joannes Broscius and Peter Crüger, and Dee as a reader of Antoine Mizauld, to Copernicus’ annotations, the ‘history of the history of writing’, and the design of printed books in the sixteenth century (for those interested, the whole programme can be found here). We also fulfilled our scholarly duty by giving papers on several aspects of AOR: Earle started with a lucid overview of AOR; Matt focused on the data aspects of AOR, discussing the ways in which we handle and view our own data; Chris presented a compelling approach to a particular element of the AOR data, the people mentioned in Harvey’s marginal notes, and gave numerous examples of how we can use network visualization in order to make sense of this data (Chris will write a separate blog post on this topic in due course); I focused on Dee’s copy of Cardano’s Libelli Quinque and compared his annotations to those of Harvey in another astronomical text, Luca Gaurico’s Tractatus astrologicus.
Several trips to various libraries in Cracow were included in the conference programme and this, together with the copious meals and the good company, proved to be the really pleasant aspect of this week. It turned out that most libraries in Poland, or at least those in Cracow and Wroclaw, have amazing collections, many of which are not well known outside (and in some case even inside) Poland, and true treasures are just waiting there to be discovered! During the days after the colloquium the scholarly tourism continued: on Wednesday we visited the Jagiellonian Library and saw (and touched!) the autograph of Copernicus’ De Revolutionibus (some low-res images can be viewed here).
In the afternoon we had the pleasure of going to Collegium Maius, the museum of the Jagiellonian University, where we encountered an actual bookwheel!
On Thursday we travelled up to Wroclaw to visit the University Library, which turned out to be truly extraordinary as one of the librarians had found, when she was preparing the show and tell, a presentation copy of Tycho Brahe’s De mundi aetherei to Johannes Praetorius! [insert image]. If this wasn’t enough still, that afternoon we went to yet another library in Wroclaw, the Ossolineum.
All in all, this was an amazing week and a wonderful combination of scholarship, bibliophilism, good company, and let’s say a more than sufficient quantity of excellent food and wine, beer, and spirits. It also proved to be a great way to get to know Poland, and many people, including myself, sort of fell in love with this country. We would like to express our heartfelt gratitude to all the people and institutions who made this week possible, in particular Clarinda Clama, who did a marvellous job organizing this week!
As the conference season has started in earnest, various members of the AOR team have travelled across the globe in order to preach the AOR-gospel. Here are some updates on the various conferences at which we presented!
RSA 2017
As part of a now firmly established ritual, several members of the AOR team (Chris, Earle, Jaap, Matt, and Tony) took part in a round table discussion on AOR titled ‘Reading John Dee’s Marginalia: Expanding the Archaeology of Reading in Early Modern Europe’. As the title indicates, the round table aimed at discussing the new avenues into which AOR is moving due to the inclusion of a second reader, the Elizabethan polymath John Dee. Tony started with a wonderful comparison of various differences and similarities between Harvey and Dee as annotators and readers, while Matt zoomed in on a particular difference, namely Harvey’s and Dee’s diverging approaches to and use of annotations. The comparison between Harvey and Dee was fleshed out even more by Chris, who compared the use of the Greek language in the annotations of both readers. Earle presented a compelling overview of AOR and explained how the new directions into which AOR is moving form a logical extension of the first phase of AOR; Jaap offered an overview of some challenging new types of annotations the Dee corpus includes. All in all, it was a lively session in which we discussed the humanistic and technical developments of AOR and had a stimulating discussion with the audience about the content of the annotations themselves as well as the best way of making them available in digital form in the AOR research environment.
CNI 2017 Spring meeting
Members of the AOR team regularly attend and present at the meetings organised by the Coalition for Networked Information (CNI), which primarily caters for an audience comprising librarians, data curators and digital archivists. These meetings, which occur twice a year, are a perfect platform for our colleagues at JHU’s Digital Research and Curation Centre to provide information about the technical (infrastructural) aspects of AOR and related projects they are working on. It also has become sort of a tradition to present a paper which combines the humanistic and technical strands of AOR. Following up on an earlier paper Sayeed and I gave at CNI’s Fall Meeting 2015 in Washington D.C., we now embarked on a trip to Albuquerque. Whereas previous time we talked about the particular model of development the AOR team has adopted, ensuring the continuous close cooperation between team members with technical and those with humanistic backgrounds, in this presentation we focused on some of the new directions into which AOR is moving, largely due to the inclusion of a second reader, John Dee, and his particular reading and annotation practices, as well as the development of new use cases and the aim to enhance and expand the functionalities of the digital research environment AOR envisages.
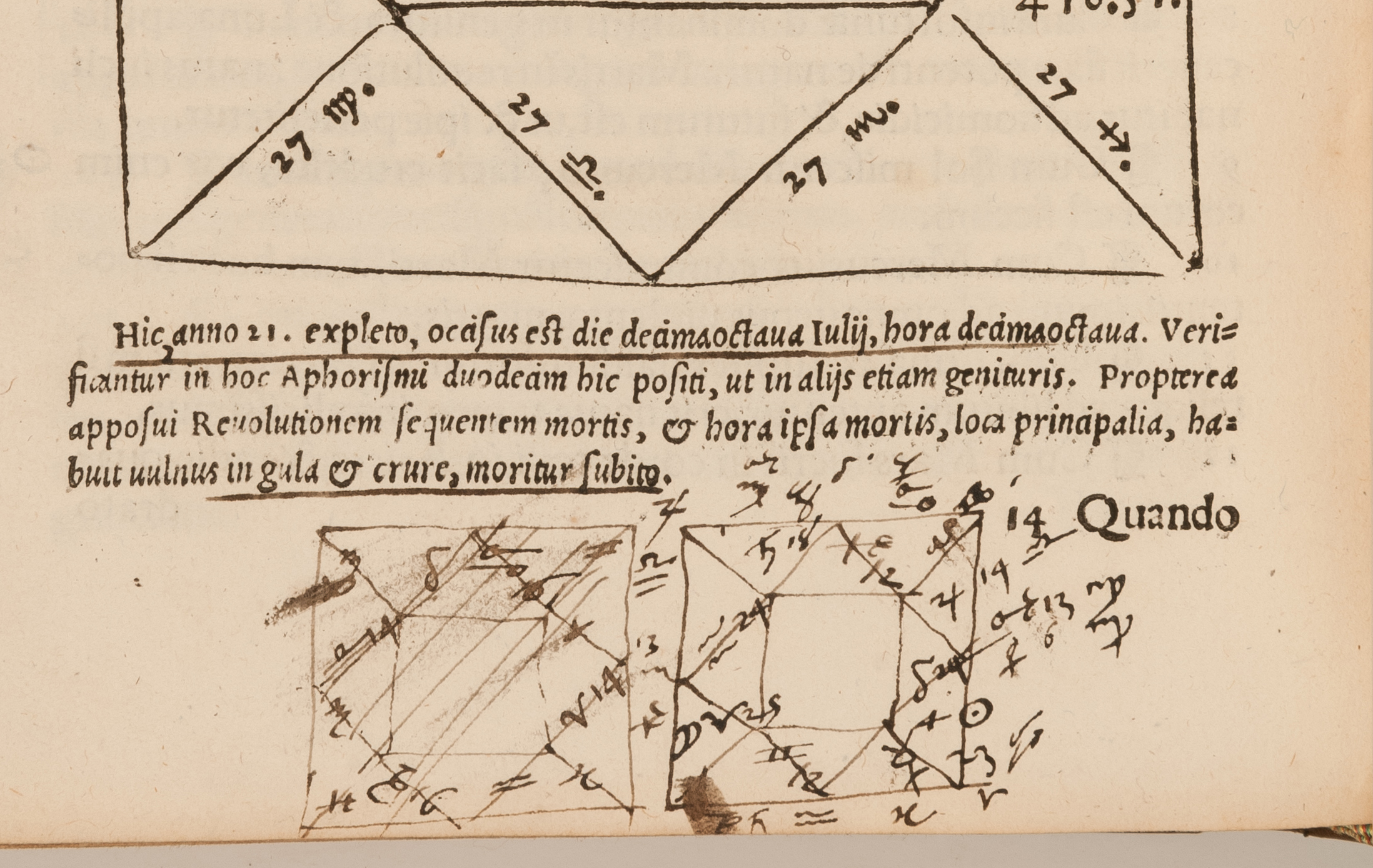
Dee’s technical annotations, such as astronomical charts, genealogical trees, and tables filled with all kinds of data, do not only pose challenges to the XML schema, but also force us to think about the appearance of what we now would call “structured data” in his annotations. We need to think how to capture and, possibly, reconstruct the relationships between the component parts of the data Dee recorded in his marginal notes. Of particular importance is the way in which we conceptualise such ‘reader interventions’, but also how such interventions are made accessible in the AOR viewer. As such, Dee’s annotations further the development of both the humanistic and technical strands of the project. Hereafter, Sayeed presented his vision of the development of infrastructure and how infrastructure can be shared among DH projects, benefitting from similarities between projects while maintaining their integrity as projects with particular research questions, sources, aims, et cetera. He then moved on to showing how some of the AOR data can be linked to other, external datasets, thus enriching the AOR data with the data generated by other (DH) initiatives. We did address other topics in our presentation and, luckily, CNI has been so kind to record it! You can view it here!
Shakespeare Association of America
While Jaap headed to Albuquerque, Matt was on his way to Atlanta for the meeting of the Shakespeare Association of America (or #shakeass, which is surely up there in the catchy hashtag stakes). SAA is organised slightly differently to most other “big” conferences: most of the meeting is given over to seminars, rather than panels, and the focus is on working together in discussion on specific themes and issues. Matt had been invited to take part in a seminar called “Traces of Reading in Shakespeare’s Britain”, organised by Rebecca Munson (of AOR Project Partner Princeton University Centre for Digital Humanities) and Philip S. Palmer (Head of Research Services at UCLA’s wonderful William Andrews Clark Memorial Library). It was especially good to get a chance to swap notes with Erin McCarthy of NUI Galway’s brilliant project The Reception and Circulation of Early Modern Women’s Writing (RECIRC). The seminar benefitted from commentary from Heidi Hackel of UC Riverside, whose Reading Material in Early Modern England (CUP, 2005) is absolutely required reading for students of annotation (and offers an intellectual approach quite different from our own here at AOR, but that’s a subject for another blog entry.)
Over the last decade or so, it has become commonplace to talk about data sets in relation to humanistic research. Whereas data sets seemed to be intrinsically linked to and part of the natural sciences, humanists of various plumage now regularly create their own. Increasingly, humanities data sets do not only contain quantitative data, such as the information amassed by economic historians, but qualitative data as well. The very process of capturing qualitative data enables scholars to study particular historical phenomena from a quantitative perspective too. Yet, I would argue, the availability of quantitative data should not replace our more ‘traditional’ methodologies which are so finely attuned to studying and understanding qualitative phenomena.
For even when qualitative information becomes quantifiable, we should not discard the richness and depth of qualitative sources; it would make little sense to conflate the fluctuations in interests rates in the early modern period with the number of times wills of early modern Catholics did or did not invoke Christ, Mary, and the saints. Even though both phenomenon are quantifiable and can be expressed in numbers, these numbers reveal entirely different dimensions of the historical past. Nor would it make sense to present the number of times poets like Joost van den Vondel or Shakespeare used the word ‘mother’ in one of their plays as a fact as such – for what does it tell us? The use and meaning of the word mother only can be grasped when taking into account various factors, including the syntax of the sentence, the meaning of other words which surround this word, and stylistic conventions. Having said that, quantitative approaches to primary historical sources of whatever kind can be very useful; ultimately, such approaches enable us to discern patterns that are not immediately obvious. Such patterns are often difficult to detect in traditional, analogue research environments. Yet the detection of such patterns should facilitate a movement ad fontes, offering a new perspective through which we can view and study our cherished primary sources. Indeed, we should strive to marry qualitative and quantitative analyses, opening up new dimensions and raising new research questions that are difficult to conceive of and pursue outside digital environments.
How does our own data set relate to all of the above? Twice during the first phase of AOR (2014–6) we numerically broke down our data set, both in relation to the creation of internal reports for our funder, the Mellon foundation. Both documents can be found here and here. One of the things we immediately realised when analysing the AOR data set is its small size: currently, even now work on the AOR2 corpus already has commenced, all the XML transcriptions amount to less than 40 megabytes. This certainly is not the size which enables one to boldly walk into a conference room to shout “my data set is bigger than yours”. (As a note on the side, humanists should refrain from doing this anyway, since the data sets of virtually everyone working outside the humanities are larger than ours.) Although size matters to a certain extent (in our case: the larger the data set, the more transcriptions it includes, and the more users will be able to find and discover), what really matters is the actual data of which a data set consists and the way in which it is captured and structured, for this determines the ways in which we can interrogate our data and what we can get out of it.
The structure of our data reflect the various types of reader interventions we encountered in the books in our corpus, such as marginal annotations, symbols, marks, drawings, tables, and graphs. This division, which closely mirrors the actual annotations practices of the readers on which we focus, makes it possible for our users to search within and across reader interventions. The AOR search widget, the child of the heroic efforts of our programmers Mark Patton and John Abrahams, contains an advanced search functionality which makes it possible to create complex, query-based searches, a powerful way of interrogating the AOR data. The juxtaposition of AOR data (the transcriptions as well as the search results) to the digital surrogates of the annotated books, facilitates an easy and intuitive movement ad fontes. In such a way, we can reap the fruits of working with humanities data while having the primary sources (or their digital surrogates) ready at hand.
Another way in which we can approach and, in a way, dissect our data set is through statistical analysis. Our thinking about the application of such an analysis started with rather mundane questions such as: “if Harvey mentions Caesar in a marginal note, which other words do frequently appear next to it?” In order to streamline such an analysis, we decided to formulate a number of concepts groups, thematic groups which include words which relate to the same, often rather broad theme, such as war, king/kingship, mind, soul, body, action, et cetera (Harvey’s own system of astrological symbols, which denote more abstract concepts, was actually really helpful in designing these concept groups). The concepts groups consists of words which together appear with a certain frequency (in order to yield statistically significant results) and include (equivalent) words of the two languages which dominate Harvey’s marginal notes, Latin and English. In generating these groups, we could make use of the lists with words and the frequency with which they appear, which are part of our recurrent data releases.
Although the formulation of concept groups was within our power, we quickly realized that none of us master the specialist knowledge and skills to actually subject our data to rigorous statistical analysis. Hence we decided to employ some professional statisticians. Once the data was made ready for analysis, an interesting process in itself which I will address in a separate blog, the statisticians started their work in earnest, mainly aiming to see whether there are any statistically significant correlations between concepts groups. In order words, do we see words which are, for example, part of the concept group ‘mind’, often appearing with words which belong to the concept group ‘body’? This makes it possible to discern links between certain topics Harvey addressed throughout his marginal notes. Although at this point in time the results of the statistical analysis are tentative, partly because our data set is slightly lopsided due to books which focus on war and strategy (Livy, Frontinus, and Machiavelli), the insights one can gain by a statistical approach are already evident. Throughout AOR2 we will continue applying statistical analysis to our data, making use of the inclusion of the second reader, John Dee. As we envisaged, results from the data analysis, even when only partial, immediately forces one to go back to the primary sources: even if there is a correlation between one or more concept groups, the individual instances of this correlation need to be tracked down and studied within the larger context of a marginal note or a set of marginal notes on a page in a particular book.
Lastly, interesting things can be done when relating or connecting our data set to other existing data sets that float around on the web. So far many data sets exist on their own, rather isolated from their peers. Over the last couple of years, the concept of Linked Open Data has rapidly become popular, as a motley crew of people comprising web architects, data curators, scholars, and scientists feel the need to link their data to that of others. This is not always a straightforward process at all, and in the future a separate blog will be devoted to it. Regardless of the challenges, the possibilities of linked data have captivated the mind of the AOR team. Already during AOR1 we realised that readers were often moving outward, for instance by referring to other books, some of which are not in our digitized corpus or are simply no longer extant. Moreover, some of our books are classical, canonical texts, such as Livy’s History of Rome, and digital editions, including translations, exist (Perseus), and it would be neat to see whether we can directly link to these editions. The concept of Linked Open Data also influences our thinking about the way we capture our data: how to transcribe the astronomical data in the Dee annotations in such a manner that it facilities an easy exchange with already existing astronomical data sets? These are just some examples of where establishing links with other data sets and digital corpora might be rewarding. Creating such links, in particular to other primary sources such as early modern annotated books, will therefore be one of the main activities of AOR2. For this moves us closer toward representing and recreating the intellectual cosmos and larger information culture early modern readers and their books were a fundamental part of.
In an earlier blog post, Cynthia York addressed and summarised the invaluable comments we received from the 34 beta testers who willingly devoted some of their precious time to play around with the AOR1 viewer and answer a number of questions we had formulated. These questions covered various aspects of the viewer, including its functionalities and design, as well as of the AOR website itself. In this short blog post, I will reflect upon some of the suggestions which appeared more frequently and the subsequent actions we will take or already have taken to address them. But before that, we again want to express our heartfelt gratitude to our beta testers: thanks ever so much, you rock!
Pinning a page
Several beta testers expressed the wish to be able to ‘pin’ or freeze a page, ensuring that subsequent actions in the viewer (searching, browsing) do not result in the ‘loss’ of that particular page. We thought this to be an important feature too, since one can easily lose important research findings when going down the rabbit hole of (early modern) marginalia. Hence one of our programmers, John Abrahams, created a button which enables one to pin the page, making it impossible to move to another image (via the browse buttons) or to open another image in the same work space. It still is possible to conduct searches and to open a search result in another workspace, however. Research thus can continue, but without the risk of losing the pinned page. There is one small glitch which remains to be solved: opening several other workspaces through the ‘change layout’ button unpins the page.
Home button
The desire to return to the gallery of books (the AOR corpus) in a simple and straightforward manner was also voiced by several beta testers. Luckily, this request turned out to be pretty easy to fulfill as the new version of Mirador (2.1) included such a home button, further improving the ease with which one can navigate.
Transcription/search panel icon
Various testers mentioned that it was not easy to find the icon to open the transcription and search panel. Although it turned out to be difficult to change the icon, we have changed the accompanying tooltip text to ‘View Transcriptions & Search’. As the real meat of the AOR content can be accessed in this panel, we might arrange that this panel automatically opens after having selected a book.
Documentation
The need for (better) documentation was mentioned frequently as well, and over the last month or so of the project the whole team has been working hard on generating documentation covering various aspects of the project, including its technical infrastructure and the functionalities of the viewer. In addition, two wonderful contextual pieces, a biography of Harvey and a short introduction to the history of reading, have been included as well. We aim to add another piece, this time on Harvey’s library, soon. All the documentation can be found here.
*.* searches
Various testers expressed the wish to be able to search for, for example, all instances of underscored text in a particular book or, indeed, all instances of a reader intervention in a book. This is a search functionality I have always been interested in myself, in particular because it’s fairly annoying to have to scroll through lightly annotated books in order to find a page which has been annotated by a reader. Including such a functionality provided to be impossible before the end of AOR1, but this is high on the to-do list of AOR2.
Highlighting the coordinate region of a specific annotation
When browsing heavily annotated pages, it sometimes is not immediately obvious where to locate a particular annotation. One way to indicate the location is to highlight a coordinate region in which the annotation ‘sits’, as done, for instance, by Annotated Books Online. However, there are a number of annotations, such as the ones who snake around a page or even across pages – as frequently happens in the heavily annotated books from the Folger, the Domenichi and Guicciardini – which can’t be captured in a system of polygons based on coordinates. Moreover, the XML transcriptions do not contain any spatial data related to the position of the annotations (and manually including these would take ages). We do describe the location (or position) of annotations on the page in the XML transcription and, realizing that some form of indication regarding the position of annotations is helpful, we have included a set of icons in the transcription panel which points at the location of a marginal annotation.
People mentioned in marginal notes as hyperlinks
Some testers would appreciate that the people mentioned in marginal notes (and which are broken out individually in the transcriptions) become hyperlinks which initiate a corpus-wide search (i.e. returning all the instances in which this person appears). Already when developing the AOR1 XML schema and, at a later stage, the document relating to the transformation of the data in the XML transcriptions to HTML in the transcription panel, we thought about this functionality. However, this proved to be quite a tricky feature indeed, so we were not able to implement it. However, this feature will be discussed for possible technological development and implementation in AOR2.
There are certainly more desiderata to be mentioned, and it was interesting to see how several comments of our beta testers overlapped with our own ideas regarding further improvement of the AOR viewer. Rest assured that we will do whatever we can to maximize the functionalities of our viewer and to further enhance the research environment AOR envisages!
The AOR team is proud to announce that several colleagues and friends have agreed to write guests blogs for the AOR-website. This is the first of these guests blogs, written by Katie Birkwood, rare books and special collection librarian at the Royal College of Physicians!
The library of the Royal College of Physicians, London (RCP) is extremely lucky to number among its roughly 20,000 rare books the largest surviving collection of volumes once owned by the Elizabethan polymath John Dee (1527-1609). Though it is impossible to pin down the extent of the collection precisely, over 150 Dee’s surviving books can possibly be identified in the RCP collection. In 2016 the Royal College of Physicians hosted the first major exhibition dedicated to John Dee and his library, displaying forty of his books alongside objects said to have been used by him as part of his so-called “spirit actions” or “conversations with angels”.
Dee was one of the most intriguing an enigmatic characters of Tudor England: famous variously as a mathematician, a philosopher, an astrologer, a magician, a mystic, and even a spy. Dee was also a determined book collector and owner of one of the largest libraries in sixteenth-century England, eclipsing those of the universities of Oxford and Cambridge combined. Dee himself numbered his library at 3,000 printed books and 1,000 manuscripts, though the evidence of his own library catalogue suggests a more conservative total.
John Dee (1527-1609). Stipple engraving by Robert Cooper after unknown artist, late eighteenth to early nineteenth century
The contents of Dee’s library were as varied as his claims to fame, covering subjects as diverse as fencing, mineral baths, falconry, and botany. The library was his pride and joy; the product of many long hours spent in bookshops in London and across Europe, and Dee’s close relationship with booksellers’ agents who could hunt out the rarest volumes. Scholars from across the continent visited Dee’s house at Mortlake (a small village on the River Thames, seven miles west of the City of London) to consult with the great scholar and to read his books and manuscripts. Members of Queen Elizabeth’s court including sought his advice on matters ranging from the appearance of a comet in the sky to possible routes to China via a north-west or north-east sea passage.
In popular culture today, Dee is certainly best known for his spiritual and angelic activities. His attempts to communicate with angels are variously portrayed as the enthusiasms of a misguided old fool, the effects of unworldly academicism taken too far, or actively malicious attempts to rule over his fellow men. However, it is the different, but perhaps equally romanticized image of Dee as scholar, seated in his study with books spread out before him, that calls most strongly to me. Dee’s annotations – by turns painstaking and passionate – speak eloquently about Dee’s life, his interests, and his personality.
Sadly, the story of Dee’s library is not an altogether happy one. Dee left England in 1583 on what would turn out to be his longest overseas trip. He left in some haste, accompanied by Edward Kelley, his ‘scryer’ – a man employed to see angelic visions in a crystal ball or other reflected surface – his wife and children, and around 800 of his books. The rest of the library, along with Dee’s globes and astronomical instruments, were left in the care of his brother-in-law, Nicholas Fromond. Fromond was not a good custodian, and let thieves into the library during Dee’s absence. When Dee returned to Mortlake in 1589 he found his house and library in disarray: the shelves ransacked and many valuable treasures lost. The popular story that Dee’s house was attacked by a local mob is almost certainly untrue; his books were probably stolen by friends, associates, pupils and others who knew their intellectual and monetary value.
Fortunately, by piecing together evidence from within the books and from the library catalogue Dee made in September 1583, shortly in advance of his departure (now Trinity College, Cambridge, MS O.4.20), it is possible to reconstruct at least some of what was lost. Around 350 volumes are identified in Julian Roberts and Andrew G Watson’s 1990 catalogue of Dee’s library, and additions are posted to the Bibliographical Society website.
It seems that a certain Nicholas Saunder (possibly a Surrey MP) was one of the thieves, or at least a receiver of stolen goods. Several of the Dee books in the RCP library have Dee’s ownership mark obliterated, with Saunder’s own name written in nearby or over the top. Saunder’s library, including other books unrelated to Dee, passed by some means into the possession of Henry Pierrepont, first Marquis of Dorchester (1606-80), whose library was given to the RCP by his family after his death.
Signatures of John Dee and Nicholas Saunder on the title page of Jean Taisnier, Astrologiae iudiciariae ysagogica (Cologne: Arnold Birckman, 1559)
Twelve of Dee’s annotated books now in the RCP library have been chosen as part of the AOR phase 2. Included in their number are some of the most stunning and revealing books in the whole collection. A two-volume folio works of Cicero annotated by Dee as a student in the 1540s provides plenty of material for the modern scholar to chew over. There’s also more than one surprise as you turn its pages. In one instance, a sketch seems to resemble a Greek temple on a small island in flames: the nearby text of Cicero’s De legibus relates how the Persian king Xerxes set fire to the temples of the Greeks on the advice of the Persian magi. A larger instance of scholarly doodling is found in the same volume. In his De natura deorum Cicero quotes some lines from the Lucius Attius describing a huge bulk surging through the foaming seas. Next to this, Dee has drawn a most spectacular ship in full sail.
Girolamo Cardano, Libelli quinque (Nuremberg: Johannes Petrejus, 1547)
Aside from star objects such as the Cicero and Cardano, a point of interest appears in almost every book that retains any evidence of Dee’s ownership or use, not only the star objects. At first glance, there’s not much of interest in Dee’s copy of Mario Nizolio’s 1544 Latinae linguae dictionarium. We can probably assume that Dee acquired the book during his years as a student at St John’s College, Cambridge. There was once an ownership inscription on the title page, erased presumably by Nicholas Saunder, and there are very few annotations within the text. However, Dee does leave at least one trace. He notes the Greek word “Lakoniken” in the margin next to the lexicon entry “scytale”. Lakoniken is an alternative name for the Spartans, and the scytale is a tool the Spartans are reported to have used to perform transposition ciphers. In other words: this single annotated word might hint at Dee’s early interest in cryptography and code-breaking.
Mario Nizolio, Latinae linguae dictionarium (Basel: Robert Winter, 1544), sig. Xx2
I’m delighted that books from our collection are part of AOR, and am excited to see what more we can start to learn about John Dee and Elizabethan scholarly culture once all of his copious annotations have been transcribed.
Katie Birkwood, rare books and special collections librarian, Royal College of Physicians, London
BIBLIOGRAPHY
Julian Roberts and Andrew G. Watson, John Dee’s library catalogue (London: Bibliographical Society, 1990)