Bookwheel Blog
Virtual Office Hours
This past week, several of the archaeologists partnered up with the Bibliographical Society of America to offer a webinar on the uses of AOR for remote teaching and research. Many thanks to Erin Schreiner for including us in the series, as well as for pulling together a wonderful list of digital resources available for use as many of us go virtual on short notice.
Here’s a quick index to the topics covered in the webinar:
[3:03] Earle Havens, What is AOR and how can I Start Using It? – introduces the project and its search and linking capabilities.
[17:35] Jaap Geraerts, AOR Search Strategies – offers a deeper dive into the search functions and AOR’s underlying data model.
[28:48] Neil Weijer, Teaching with AOR – walks through the exercises and types of activities available on the “Teaching with AOR” pages, and how to begin creating your own using the HTML Export capabilities in the viewer and the resources on the AOR site.
[42:50] Matt Symonds, AOR as Part of a Wider Online Research Environment – explores how the external links in the viewer can be used to pursue research topics in the broader landscape of digital early modern books, and some suggestions where to start.
The notes from our presentations, along with a subject guide to the digitized books in the AOR viewer, are available on our “Downloads” page. All of them contain links to pages in the viewer, as well as resources on our site. We hope that it helps those of you looking to incorporate virtual rare books into your syllabi for the remainder of this semester and in the future.
The series of webinars on digital resources, along with links to recordings, are available on the Bibliographical Society of America’s website.
Be safe, everyone.
School’s In Session

As the new academic year comes rolling in, we’re ready to hit the books again. We’ve added a few new elements to the site that we hope you’ll find useful.
Our pedagogy pages are up and running. On them, you’ll find exercises aimed at a range of users and applications, from undergraduate and graduate seminars to high schoolers and autodidacts. The modules on each page can be used individually, or incorporated as a series of exercises over the course of a semester or class, and introduce key questions posed by our books and readers along with the functionalities of the viewer. Each exercise contains step by step instructions, but if you or your class is new to using the AOR viewer, you may want to consult our How to Use AOR page. If you’ve had success using them, or adapting parts of the viewer in your own coursework, we’d love to hear from you.

One of the things we learned over the four years of developing the project is that the questions we were asking ourselves and our colleagues on a daily basis shouldn’t be hidden from view. Nor should our solutions to them be presented as definitive. The exercises on these pages represent some of our discoveries and thoughts, with additional background readings and room for expansion. As our readers and annotators demonstrated to us time and again over the course of the project, there is no end to the learning that can be drawn from these books, but that they depend on the knowledge that is brought to them. Our “Remaining Questions” section at the bottom of the pedagogy page pulls together a selection of these puzzles that left us collectively scratching our heads.
If you’re looking for more reflections on the material on the site, all of the video from our January symposium is now live on the website. Head to the Symposium Video page to hear our archaeologists discuss different aspects of the books, viewer, and the project.
Looking Back, Looking Forward
It’s been a busy few weeks here at AOR as we look to finalize the content of our website, and it’s hard to believe that our London symposium took place over a month ago!
 It was encouraging to see so many old and new faces in Senate House for our symposium, and to hear the ways that working in AOR has helped scholars investigate so many different aspects of Harvey and Dee’s books. Our presenters offered everything from close readings of individual annotations and drawings to sweeping, data-driven analyses that looked at the ways that Harvey and Dee employed language in their books. We were also able to give a sneak peek of the nearly-released viewer, which the attendees could use to explore the books under discussion.
It was encouraging to see so many old and new faces in Senate House for our symposium, and to hear the ways that working in AOR has helped scholars investigate so many different aspects of Harvey and Dee’s books. Our presenters offered everything from close readings of individual annotations and drawings to sweeping, data-driven analyses that looked at the ways that Harvey and Dee employed language in their books. We were also able to give a sneak peek of the nearly-released viewer, which the attendees could use to explore the books under discussion.
The mix of projects and questions really drove home a concept that we’ve been seeing in Dee and Harvey’s books (as well as in our own working methods as we transcribed and encoded them) – that this type of inquiry, whether in the sixteenth century or the twenty first, is at its best when it is collaborative. The data provided by the transcriptions allowed some of our presenters to dive deeply into questions that would have only been able to be addressed in a very limited sense in any given book, such as the use patterns of individual words. It was rewarding to see how the traditional, context-heavy studies of annotation in books reinforced each other, and made for a productive discussion of just what these things that we call annotations (or marginalia) actually are, and what they have to do with reading as we understand it today, or how Harvey and Dee understood it in their own time.
We’ve also been thinking about the ways that digital projects can and should change to keep up with their surroundings, and the fact that they’re never truly “done” in the sense of fixed, stable publications. As we concluded the symposium, Winston Tabb, Steve Ferguson, and Katie Birkwood led a panel on the development and management of digital projects like AOR in research libraries, and offered some insight on what “preservation” means in the digital age.
We also took the opportunity to record the thoughts and impressions of many of the archaeologists who have worked on the project since its inception (and in some cases before), a small teaser of which is above. They’ll be uploaded soon, so please watch this space. As we continue to look back over the AOR website and update the content, we’re well aware that we’re working in a perpetual present, and we’re happy to have these little time capsules back into the project phase available for you to see.
All in all, the symposium was a fitting milestone for the project, and a great sign of potential developments to come.
The Updated AOR Viewer is Now Live
Happy Fri-Dee, everyone.
After much transcribing, tinkering, and typing, we’re happy to unveil the fully-updated Archaeology of Reading viewer! We hope it provides a functional and sharp facelift to the Gabriel Harvey books, which are now joined by the 23 volumes annotated by John Dee. Now you can finally see what we’ve been blogging about for the past year and a half. Feel free to stop reading at this point, click on the red “Go to AOR Viewer” button above on the masthead, and dive in!
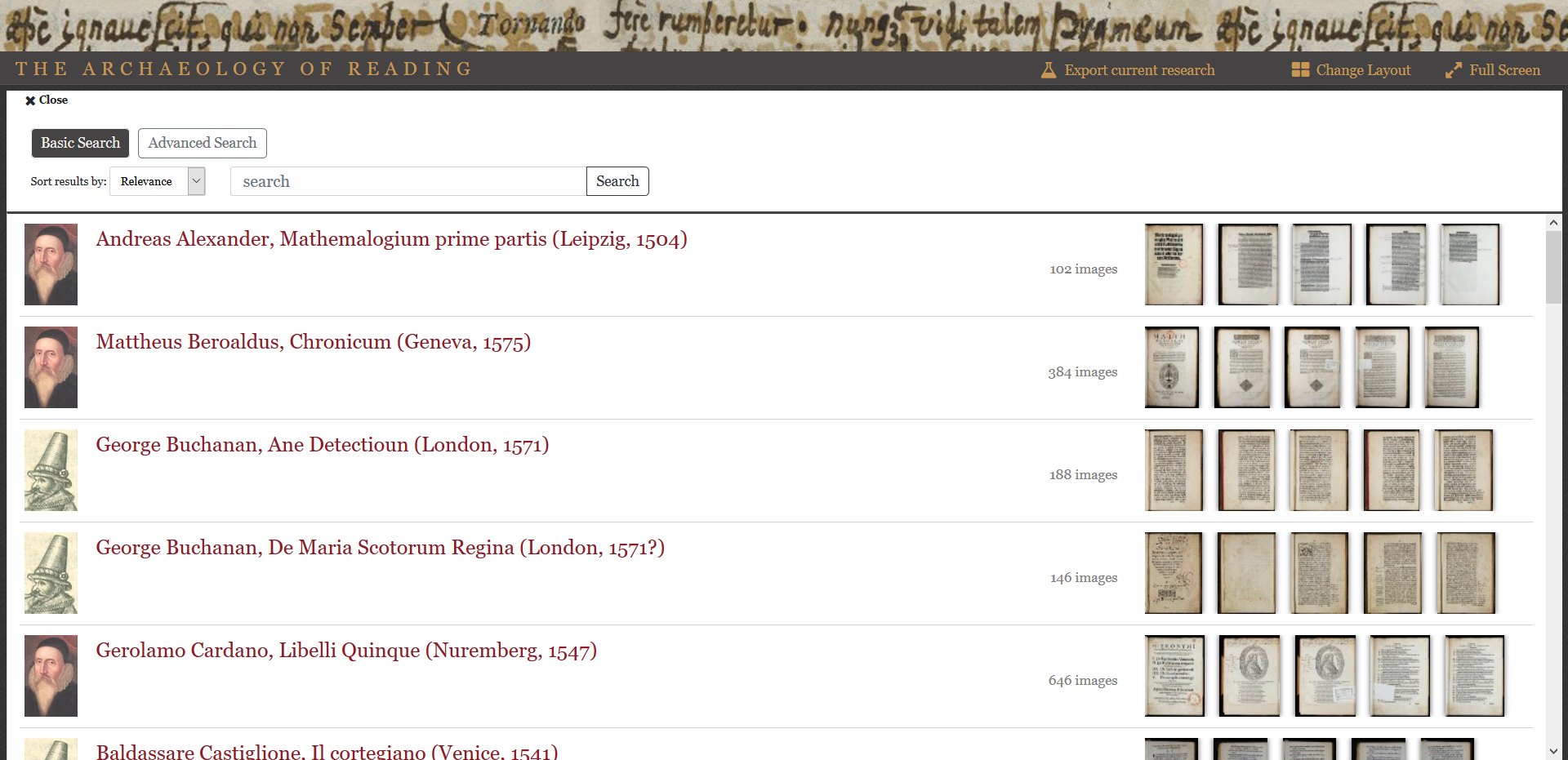
While more detailed descriptions of how to use the viewer are available here, it might be good to call out a few particularly useful features. While all the books appear alphabetically by author in the gallery, the icons next to them will let you know who read which one.
Secondly, the tagged materials in each note now appear as live links, which can be used to initiate searches within and, in some cases, outside the viewer. Clicking on any one will give you the option to search for it within the book or the entire AOR corpus.
For books and people (documented ones anyway) mentioned in the notes. you also have the option to go to the record preserved in the Universal Short Title Catalog (USTC) or their International Standard Name Identifier (ISNI). As we said, you won’t be able to do this for the legendary British monarchs found in Geoffrey of Monmouth, but you can still search for them in other places (as Dee did when he read historical books)
Lastly, our viewer now features stable URIs for each image in the corpus, as well as some states of the viewer (such as searches). These can be pasted into a browser to immediately refer back to the page you were on, and can also be exported as a list by using the “Export Current Research” button in the top right of the header. You’ll be able to select the pages or searches you want to save and annotate them as a list of links in HTML, or, if you’re more graphically inclined, as a Distributed Scholarly Compound Object (DiSCO) in RMap. If the last part of that sentence didn’t make sense, don’t worry, but we hope that RMap will give the opportunity for searches, findings, and other observations to layer onto each other, and for researchers to see how this particular group of books is being read currently (meta-AOR).

Our WordPress site has also undergone some modifications. Descriptive essays for all of the books in the corpus, as well as the larger libraries that they were drawn from are now available in the “Books and their Readers” tab. Click through them to learn more about the tale of two libraries this project now tells.
A huge note of thanks is due to those of you who beta tested a version of this site over the holidays. We were able to do some last-minute adjustments to the search bar, in particular, to make the resource more easily navigable. The viewer wouldn’t look as nice as it does without the efforts of our resident technologists at the DRCC, and the creative eye of Cathy Shaefer and her team at SPLICE Design Group.
We hope that you enjoy the viewer as much as our sixteenth-century readers would have. We’ll be adding more video and teaching content to the site over the upcoming weeks, so watch this space for more!
Down to the Detail of Dee’s Greek Marginalia
Happy New Year from the AOR team! In order to start 2019 and the last month of AOR with a bang, here’s the blog written by our research assistant and newly-minted doctor Juan Avecedo!
I have spent some weeks transcribing Dee’s Greek marginalia in the AOR corpus, which includes mostly topical notes, a few citations from related Greek works, and occasionally also a reference to a significant Greek associated concept. So, apart from the citations, which are rare and can be a few lines long, his Greek notes are very succinct and to the point. It is known that in other works, as in his diaries for instance, Dee used Greek for reserve’s sake, like for private notes, so much so that he referred to himself with the Greek acronym Δ. But in the AOR corpus, his Greek notes are mostly limited to technical terms in rhetoric, astronomy, geometry, astrology and other fields. This is why what I have found more interesting in this short acquaintance is the privileged glimpse into the intimate relation between a scholar like Dee and the Greek language.

Rabelais famously spoke of Greek being transmitted from hand to hand over the centuries like a secret knowledge, and with Dee one is struck by how the use of Greek is effectively a persistent evocation or rather, properly, an invocation of the original sources of knowledge, and thus a permanent reminder. I would suggest that in his marginalia the use of Greek is a reminder in two complementary ways: a very practical one, namely the recalling of technical terms and expressions; and another way, more philosophical and more direct, whereby we are reminded of that ‘hand to hand’ continuity, of the ever present, ever available treasury of Greek literature and knowledge.
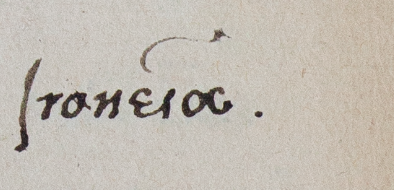
Another interesting question that leaps from the annotated pages is the extent of Dee’s proficiency in Greek. It is known that upon the foundation of Trinity College, Cambridge, in 1546, he was appointed under-reader of Greek, so he must have obviously been adept at teaching Greek. He possessed a number of Greek books which he marked and annotated copiously, so it is obvious that he was used to reading it too. What his Greek annotations reveal is, I believe, the insouciance of the true expert. His annotations are for the most part fully accented, which is no mean accomplishment in Classical Greek, but sometimes they are only partly or wrongly accented, or even mixing Latin and Greek letters. What this tells us, especially when contrasted with lengthier passages copied verbatim without any mistake, is that the majority of his Greek notes were made impromptu, without a model, and this would not be the case if the writing of Greek had not been a familiar activity to him. It is hard to tell how he would have compared with his contemporaries in this regard, but against our current standards, and upon the scrutiny involved in these transcriptions, I feel one can confidently say that Dee was an accomplished Hellenist in every way.
The challenge of … page numbers
We have arrived in the last months of AOR, which is scheduled to come to an end in late January. This means that we are busy with getting the next version of our digital research environment ready. Part of the remaining work is very exciting and comprises the creation of a set of contextual documents on John Dee, his books that are in the AOR corpus, and his library. To that end, a humanities meeting was recently held at Princeton’s Institute of Advanced Studies (see Neil’s blog for more information). Necessary but unfortunately somewhat less exciting is the work that takes place in the trenches: checking transcriptions, hunting down bugs, and testing the viewer. This blog post addresses a problem which has haunted us over the course of AOR and which we had to face head on last month.
The problem is a rather mundane one: displaying the correct page numbers of a particular book in the AOR viewer. Getting this right proved to be labour intensive, while the problem itself shows the tension between the ways in which a (digitized) book as an object is viewed from distinct humanistic and technical perspectives. The problem emerged due to a combination of the particular technical infrastructure inherited from earlier projects conducted at Johns Hopkins University (JHU) and our transcription policy. Based on earlier work on the Roman de la Rose and the Christine de Pisan projects, the digital images that are ingested into the JHU archive are labelled according to the sequence of manuscript, starting with 1r, followed by 1v, and so forth. This folio numbering system both reflects the objects on which these projects focused, medieval manuscripts, as well as the conceptualization of objects within IIIF viewers as a sequence of images. However, anyone vaguely acquainted with early modern imprints will now that the page number system of these objects in general is much more complex because of the combination of page numbers and signatures, with some books having separate sequences of page numbers and/or signatures for individual sections.
As a result of the internal system of attributing page (i.e. folio) numbers, a mismatch between the page numbers visible on the digital images and the page numbers displayed in the bottom of the viewer emerged, as shown on the image below.

One way to overcome this hurdle was to include information about the page number and signature in the XML transcriptions generated for the project and to display this information in the viewer. We managed to get this working in the new version of the viewer – which currently is under construction and not yet publicly available – but quickly realised that this problem continued to persist in a number of cases. This was caused by our decision not to create XML files of all digital images, but only of those that contain one or more reader interventions, that is, any visible interaction of a reader with that page. Since at least around half of the pages in the books which are included in the AOR corpora are not annotated, XML files for these pages do not exist. As a result, for the pages which do not have an XML file associated with them, the viewer returns to its internal numbering system, creating an extremely awkward combination of page numbers and/or signatures and folio numbers (see below).
![]()
Several possible solutions existed, including the creation of a XML transcription for every digital image in the AOR corpora. This would mean having to create several thousand XML transcription which, although the transcriptions themselves would be small, would take in inordinate amount of time. The other, more feasible option was to create spreadsheets for every book in the AOR corpora which comprise information about the file name of the digital image and the information about page numbers and/or signatures (in the absence of the former) contained in the XML transcriptions. Luckily the junior programmer working on AOR, John Abrahams, was able to generate these spreadsheets, which meant that I ‘only’ had to enter manually the information regarding the page numbers of the digital images which do not have a transcription associated to them.
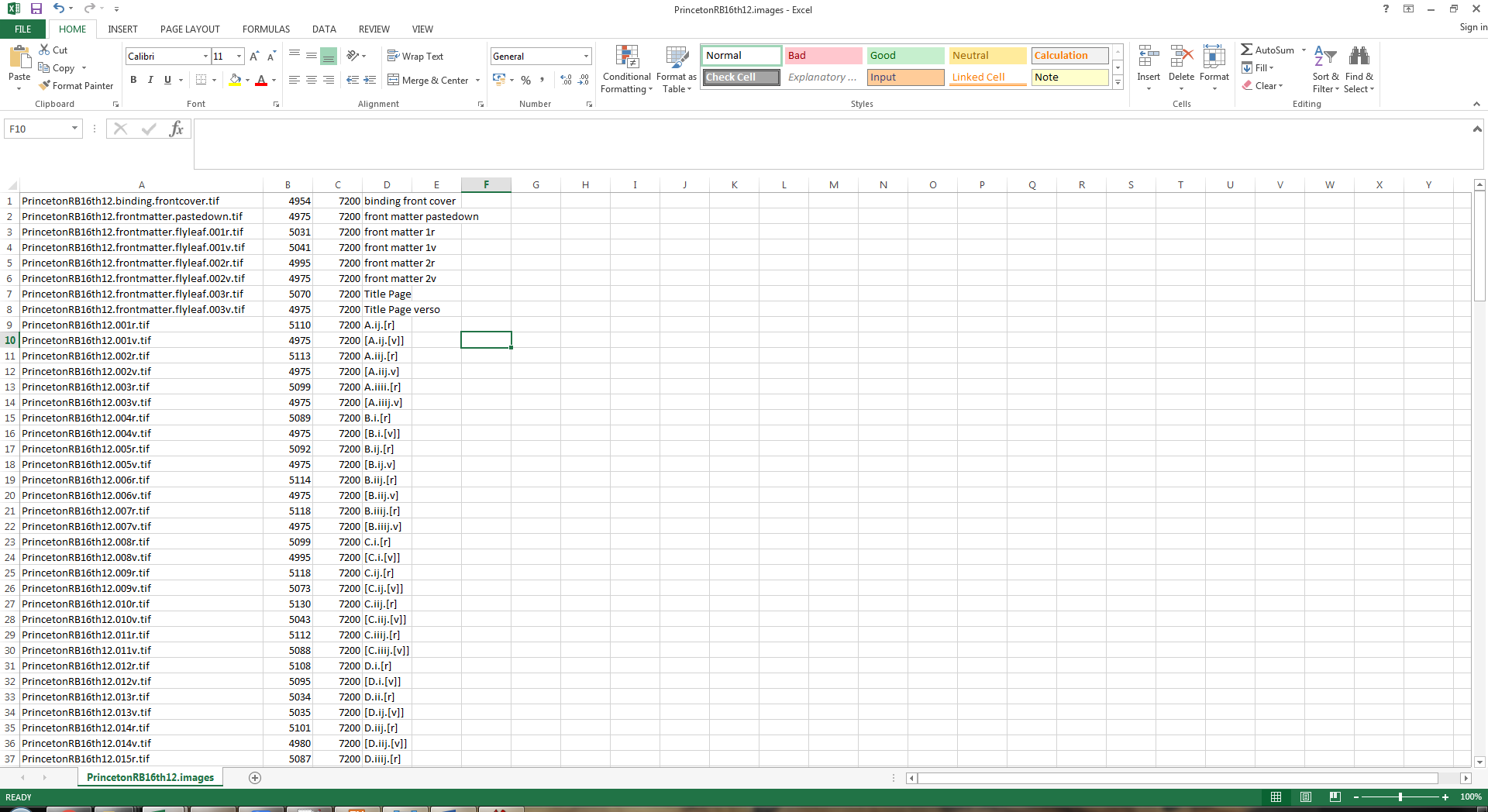
Nevertheless, I still had to go through 35 spreadsheets, check the information provided in them, and add/amend data where necessary. This process was further complicated by the mismatch between the file names of the images to which we refer in our transcriptions and the file names that are used internally in the JHU archive. These internal file names, created during the process of ingesting the digital images into the JHU archives, were provided in the spreadsheets. Based on the data in the transcriptions, I had to match the two sets of file names and then add the correct information to the spreadsheets. While being motivated by the thought that finishing this work would constitute an important step towards beatification, and spurred on by listening to football shows and a healthy dose of death metal, I did manage to populate all the spreadsheets. Although the work itself was everything but interesting, the final result is all the more pleasing. The information provided in the new version of the AOR viewer now matches the page numbers and/or signatures of the early modern imprints. Apart from avoiding confusion, this makes navigating these annotated books and doing research in the AOR digital environment much easier. Moreover, during the process of going through the spreadsheets, I encountered a couple of bugs (e.g. transcriptions being associated with the wrong images), constituting an additional fruit of this work. Apart from being a heroic story of sacrifice, perseverance, and the divine combination of football and metal, this blog shows the extent to which the spade work, done by both by computer engineers and humanists, forms the rock upon which this digital resource is built.
Project Update: John Dee Meets Albert Einstein
Two weeks ago, a good portion of the AOR Humanities team convened at the Institute for Advanced Study in Princeton for one final meeting before we all meet in London to celebrate the end of the project! Unlike March’s meeting on Dee and his books, the only complications getting all of us in the room came from a few stray Skype outages, a welcome change from the blizzard-induced panic that marked our first group session. There’s a lot left to do before we roll out the viewer, but the meeting was an excellent chance to take stock of how far the project has come, and how best to encapsulate the many uses that Dee and Harvey found for the small subsets of books we’ve drawn from their respective libraries.
After months of transcription work, the massive amount of data from Dee’s annotated books is nearly ready for analysis. The weeks leading up to the meeting were spent ensuring that we had the best, and cleanest possible data set to send out. The culmination of that exercise was an afternoon of scribblemania, as we put our heads together to try and decipher the considerable list of illegible, questionable, or otherwise incomprehensible annotations clinging on for dear life in the margins of Dee’s books and the comment fields of our XML transcriptions.
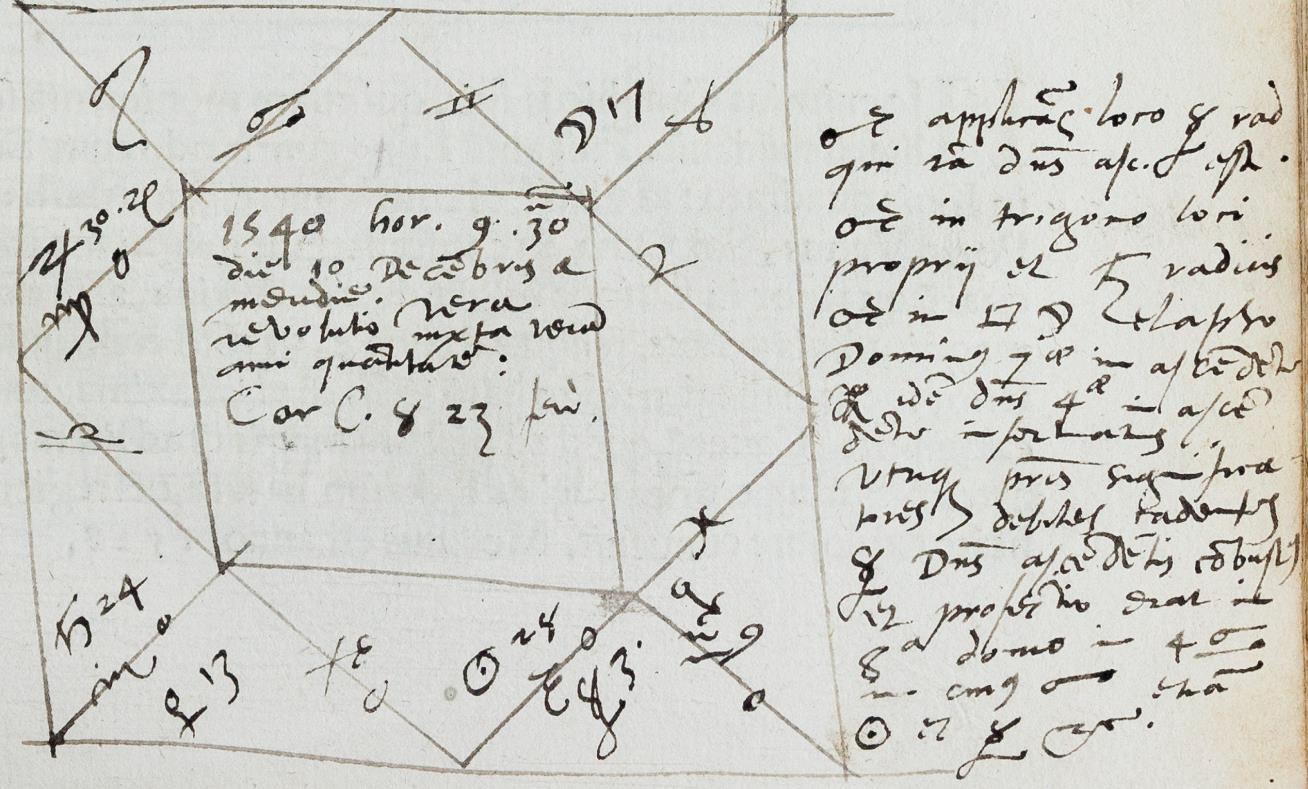
(Cardano, Libelli Quinque, p. 182)
Some of the astrological marginalia proved the most stubborn of the lot. Cardano’s Libelli Quinque had a number of holdouts, since even knowing the language they were written in wasn’t a guarantee that they’d be comprehensible. Tony Grafton set the gold standard for conundrum cracking on the day when he extracted “Ophiuchi” from this semi-legible note in the bottom corner of Dee’s corrections to Cardano (p.229).

The rest of us then learned that Ophiuchus is a constellation, which we’re now happy to pass on to users of the viewer. Conversations like this one have played out virtually in the comment fields of our transcriptions, but having them in person is always a treat, and a great reminder of how multiple perspectives can enrich the readings of books like these.
Banishing stubborn marginalia wasn’t the only fun that we had during the trip, we also had the chance to look over the Institute’s stellar collection of rare books in the history of science, begun by Lessing J. Rosenwald. Highlights of the many wonderful books that Marcia Tucker, the Historical Studies Librarian, pulled out for us to see included an annotated and expurgated first edition of Copernicus’ De Revolutionibus, along with a newly acquired collection of Spinoza’s works, including his Tractatus theologico-politicus with not one, but three false title pages attached.

We’re now hard at work on the concept groups for the Dee corpus, which should provide a good glimpse into how differently these two men approached their books. We’re also making tweaks to the new version of our viewer, which should be out for beta testing in the next few weeks. Watch this space!
Annotated Books at UCLA: Wider Applications of the AoR Schema
This guest entry comes from Philip Palmer, Head of Research Services at the Clark Library at UCLA. Philip writes about his experience using the AOR schema to encode transcriptions of annotated books held at UCLA
In July of 2014 I started a CLIR postdoctoral fellowship at UCLA’s Clark Library on the subject of “Manuscript Annotations in Early Modern Printed Books.” Less than a month into my postdoc The Archaeology of Reading in Early Modern Europe (AOR) project was announced, and naturally I was excited about potential discussions and collaborations with Earle Havens and his team. The Clark hosted a symposium on annotated books in December of that year, and both Earle and Matthew Symonds were in attendance. At this symposium an international group of scholars, librarians, and curators discussed various topics related to the study and curation of early modern manuscript marginalia; the symposium also coincided with the beginning of a pilot project to digitize ten annotated books from the Clark Library’s collection (since expanded to 60 books from our ongoing NEH digitization project, about which more info to come below). Since the symposium, the AOR team was generous to meet with me about the XML schema they developed and encouraged me to adapt it to the annotated books digitized at UCLA.
One of the main differences between the AOR corpus and the annotated books digitized at UCLA is the latter’s more variable range of annotators and annotation types. Several of the annotators are anonymous and most are somewhat obscure, with only one from the original ten books being a canonical writer (the playwright and literary critic John Dennis). None of these readers annotated more than one book in the group of ten, unlike the focus on two specific readers in AOR. The Clark readers also take many different approaches to their annotations. A copy of Sir Thomas Browne’s Pseudodoxia epidemica (2nd ed. of 1650) annotated by a seventeenth-century English lawyer comprises a complex layering of cross-references to work by Browne and other contemporary scientific texts. Being one of a handful of copies bearing errata corrected in the hand of John Florio, a copy of the 1603 English translation of Montaigne’s Essayes contains marks and marginalia made by a reader in the 1680s—a reader preoccupied with how Montaigne “talks of himself.”

Another book in the UCLA corpus—Richard Allestree’s The Art of Contentment (1675)—features casting-off marks and marginalia made by a printer or compositor, presumably to plan a new edition of the text (though this new edition never materialized). Also digitized is a copy of Aleazar Albin’s The Natural History of English Song-Birds (1779), annotated in the early nineteenth century by an avian enthusiast named Judith Gowing, who supplemented the printed text with handwritten advice on bird-care (and a bit of taxidermy)

The six other books initially digitized from the Clark’s collection range from polemical critique in a 1724 edition of Confucius to devotional marginalia in a 1708 spiritual autobiography. In other words, there is not a common theme, method, or reader in the annotations digitized from UCLA; rather, these ten books are representative of the characteristic idiosyncrasy that historical readers brought to their material readings of books.
With support from the UCLA Digital Library to digitize these ten original volumes, the next step for our project involved transcribing the annotations. At first I explored the viability of using the Text-Encoding Initiative’s (TEI) standards to transcribe and mark-up a test set of transcribed annotations (from Roger Ascham’s A Report and Discourse of 1570). One good reason to use TEI in this case was the existence of an encoded file of the printed text of Ascham’s Report, created through the Text Creation Partnership (TCP) at the University of Michigan. The existence of this file meant all I had to do was add the text of the manuscript annotations to the existing transcription of the printed book and edit the TEI Header (the Oxford TCP website is a good place for finding such files). But one big problem is that TEI is not designed for dealing well with manuscript marginalia and cannot achieve the desired level of granularity in its encoding.
Serendipitously, it was also around this time that I met with Earle, Jaap, and Matthew to discuss the AOR XML schema and how it might be used for non-AOR projects. I was impressed with the level of detail possible with AOR markup, especially compared to the limitations of TEI for annotation encoding. While I did not plan to make too many changes to the AOR schema, there were a few small tweaks I made to accommodate the idiosyncrasy of the Clark Library annotated books. These tweaks included adding more values for handwriting type and marginalia topic, refining the way internal cross-references are encoded, and creating a new attribute for “marginalia type” within the <marginalia> element.
A month or so later the Clark Library applied for and received a small grant from the Gladys Krieble Delmas Foundation that enabled us to hire three UCLA graduate students to transcribe and encode this original corpus of ten annotated books. Two English students (Samantha Morse and Mark Gallagher) and one History student (Sabrina Smith) spent three months during the Summer of 2016 transcribing and marking-up the annotations in seven of the ten books. (The annotations in two books—Sir Richard Blackmore’s Prince Arthur and Voltaire’s Dictionnaire Philosophique—proved too voluminous for the students to finish.) On day one I offered a three-hour crash course in early modern paleography and XML text-encoding; the session was supplemented by a detailed training manual. To make the encoding process easier the Clark purchased the Oxygen XML editor software for each student.
As the transcription project was intended to pilot workflows and methods for transcribing and encoding annotated books, we were just as interested in learning about process as we were in the product of the transcribed annotations themselves. For each of the student transcribers, the beginning of each book posed difficulties, primarily related to learning an individual’s handwriting quirks. XML encoding presented a challenge as well, though the combination of the training manual, AOR schema, and Oxygen’s auto-complete feature helped our transcribers grow accustomed to the work.
This pilot project also entailed comparing the TEI-encoding of manuscript marginalia with transcriptions made according to the AOR schema. Of the seven books the students completed, two were transcribed with TEI mark-up rather than the AOR schema. In both cases, these books are available as existing TEI files through the Text Creation Partnership. In the end we concluded that the AOR schema was preferable for marking-up text to enable research on manuscript marginalia: it captures much more information than is possible with TEI, including the ability to mark-up non-textual annotations such as underlining and symbols. The one aspect of TEI-encoded annotated books I do like, however, is the ability to mark-up both the printed text and the manuscript annotations. (The AOR schema only captures the annotations themselves, though encoding an entire printed text by hand on top of the annotations is a prohibitively time-consuming enterprise!)
When the three-month transcription phase of our project ended in September 2016 there was still much additional work to be done. First I had to edit the transcriptions for accuracy, which proved to be one of the most time-consuming aspects of the project. Next I had to plan how I would display these transcriptions and digitized annotated books online without having to hire a team of programmers. We at the Clark have been fortunate to partner with the UCLA Digital Library and California Digital Library to publish the digital scans of these annotated books on Calisphere, which is a digital object platform for libraries in California, especially from the University of California campuses. The ten digitized books were published on Calisphere in mid-March 2017. But earlier in the project, when preparing the digitized books for transcription work and developing a website to showcase the transcriptions, it was necessary to upload the scanned pages to the Internet Archive, primarily so we could start exposing these annotated books to a wider audience. And since all Internet Archive digital objects now conform to the International Image Interoperability Framework (IIIF) metadata standards, it was possible for me to display our annotated books using IIIF on a custom website. (Calisphere will be using IIIF in the near future too.)
Without going into too much detail, I was able to transform automatically every XML file produced by our student transcribers (one file per annotated page, which amounted to 1,141 total files) into individual HTML pages. I then created a simple website (using nothing more than HTML, CSS, and JavaScript) showcasing those pages and contextualizing each annotated book with introductory material. With funding for further application development it would be possible to build an XML database with front-end search functionality, but for now this site does a reasonably good job presenting annotated book page images side-by-side with transcribed marks and marginalia. In the near future we hope to add our student transcriptions directly to the Calisphere website showcasing our digitized annotated books.
In fact, the Clark won an NEH grant in 2016 to digitize over 250 early modern annotated books, so the Calisphere collection will grow considerably when the project concludes in October 2018 (60 books currently available). Combined with the Clark’s recently completed CLIR grant to digitize over 300 early modern English manuscripts, the Calisphere collection will become one of the largest digital repositories of early modern English manuscript material when both projects are completed.
During all of these digitization and transcription activities it has been wonderful to work with the AOR team and watch developments in their project. As anyone who has worked on Digital Humanities projects knows, it is never a good idea to “reinvent the wheel,” and the existence/accessibility of the AOR XML schema has ensured that the Clark Library annotated book transcriptions are largely interoperable with those produced for the marginalia of Gabriel Harvey and John Dee. I encourage any other annotated books projects out there to follow our lead and re-use the AOR schema for your transcription work, as Earle, Matthew, and Jaap have been extraordinarily generous in sharing their work with the larger academic community.
John Dee’s IDs

Blizzard aside, it was great to take AOR on the road for this year’s Renaissance Society of America (RSA) conference in New Orleans. Some great conversations emerged from discussion of Dee’s books, both in and out of the corpus. During the panel “Paging John Dee” Stephen Clucas pointed out a feature of Dee’s notes in his alchemical manuscripts that had caught my eye in the Geoffrey of Monmouth: a number of annotations bearing the initials “I.d.” Encountering these brought to mind a similar question for both of us: “why did Dee sign some annotations and not others?” and, more generally “what could this practice mean?”
Since mentions of people in our individual annotations have been tagged, a quick search of AOR for “John Dee” (in quotation marks) in the person field of an annotation yielded 46 results across 16 of the 22 Dee books we have transcribed.
This search required a little cleanup, as it captured annotations that included references to Dee or his books, or Dee’s ownership inscriptions on a title page. Eliminating those revealed 28 signed annotations across 9 different books.
| Title | Number of Signed Notes |
| Monmouth, Historia regum Britanniae | 9 |
| Cardano, Libelli quinque | 6 |
| Paris, Flores historiarum | 4 |
| Maternus, Astronomicon | 3 |
| Walsingham, Ypodigma Neustriae | 2 |
| Paracelsus, Baderbuchlin | 1 |
| Pantheus, Vorachadumia | 1 |
| Cicero, Opera | 1 |
| Alexander, Mathemalogium | 1 |
A few observations jump out from just the data. First, some texts appear to have been signed more heavily than others, with the Geoffrey of Monmouth signed the most extensively. Good to know that I noticed these notes after being beaten over the head with them (comparatively speaking) in the Monmouth. More specifically, these appear to be Dee’s way of editorializing and, in particular, problem-solving, as he does here, in explaining a correction to Maternus.
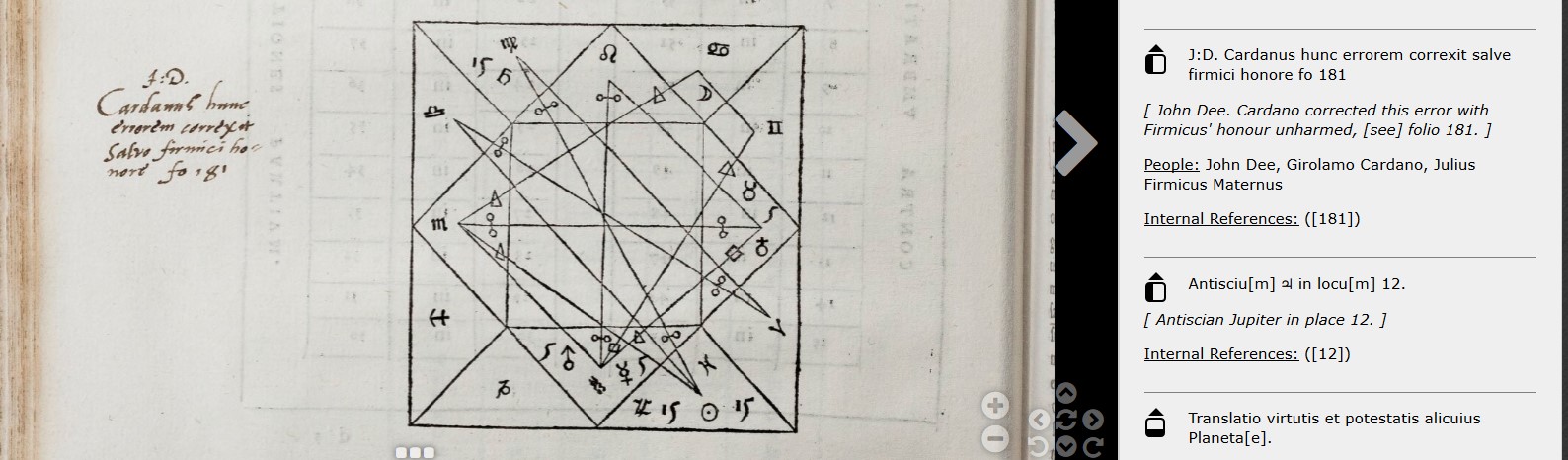
Or here, questioning the lineage of Britain’s earliest inhabitants.

Second, in the books with multiple signed annotations, the signed annotations appear to cluster together. Flyleaves and endpapers are consistent candidates, but within the body of the text, for example, we find a succession of signed notes in the Monmouth (fols 15-19) the Cardano (fols 56-63), along with two other signatures next to Dee’s work on tables.
However, in the Cardano, some of these readings are dated, a trend observed in other books that Dee read around 1554-55 like the Mathemalogium, which records the date (and location) of Dee’s shared reading of the text in a Harvey-like note. 
By contrast, only one signed annotation in the Monmouth is dated, chronicling Dee’s discovery of a corrected manuscript that supports his (earlier) assumption about ancient place names, discussed in this earlier post.
Some cautions here about the value of data alone – the clustering of signed annotations within any particular volume may be reflective of the overall clustering of annotations. Without broader context, we might not know how representative of a certain genre, time period, or topic this type of intervention is. It isn’t possible to locate all the books in Dee’s library catalogue, and even if we could (as I’ll leave for another post) we know that these aren’t the only books that he was able to put his hand on. Because such rich records survive, and because Dee was such a distinct annotator and intellectual figure, we know enough to locate books that aren’t mentioned in the catalogue that have Dee’s annotations.
However, searching the entire corpus cast light on tendencies that I never would have encountered had I just been looking at Dee’s “historical” books (or indeed, just the Geoffrey of Monmouth). His dating of annotations, in particular, seems to have peaked at an earlier period than his notes in the Monmouth volume. It also allows us to observe Dee actively engaging in conversation with his books (clarifying material and posing questions) and, we must assume, the other readers that encountered them in his library. Even if these outputs don’t fit into neat or, for that matter, readily apparent categories, they allow us to ask questions that wouldn’t be askable of one book, or perhaps even one note in one book. Pulled together quickly, this zoomed out view of Dee’s reading helps test initial questions like “why would Dee ‘authorize’ his own notes?” and tie them to new discoveries in the field.
This approach might also help scholars to identify practices to investigate beyond the corpus. On the same RSA panel, Jenny Rampling showed how far Dee’s notes might travel, tracing one out of the margins of an alchemical manuscript and into a printed book, via a fair copy made at the request of Dee’s traveling companion and “seer,” Edward Kelley (1555-97). If the notes in these books were Dee’s intellectual property, the Q&A session also revealed an early example of its theft: Nicholas Saunder, who made off with books from Dee’s library and tried to disguise their origin (as he has in the Pliny), appears to have written over Dee’s initials in the marginalia as well. Just as we “encounter” Dee in the margins of his books, so too did his contemporaries. What might their impressions been of him?
Defying interpretation? Topical marginalia and the history of reading
At the most recent conference of the Renaissance Society of America (RSA) in New Orleans, I planned to speak about the difficulties in writing a more general history of historical reading practices and offer several possible solutions. More specifically, I wanted to explore various strategies which can be employed in order to examine similarities and differences in the reading practices of Gabriel Harvey and John Dee. Sadly, though, a winter storm prevented me from leaving Princeton and ultimately from giving my paper as I only arrived in New Orleans on Friday afternoon (hence missing out on most of the conference). Although my paper was unlikely to revolutionize the field, some of the issues I address are relevant to those working on the history of reading. I therefore would like to make use this space to briefly discuss one particularly vexing problem, namely the difficulty of incorporating topical marginal notes in our analysis.
According to Bill Sherman, a ‘topical note’ are those marginal notes which acted ‘as a concise key to the topic of a passage’ (Sherman, Dee, 81). In general these notes consist of a just few words, often copied from the printed text, which indicate the main topic of a section. It is not that these topic notes completely escape the possibility of scholarly analysis: at their very core they show the particular intellectual interests of a reader. When having the advantage of working with a known reader, such as Dee and Harvey, knowledge of the historical context is of invaluable help when trying to make sense of such annotations. As Sherman remarked, ‘Dee’s notes in these passages [in some medieval books] are rarely interesting in themselves…but their value lies in the fact that he consistently drew attention to the material that would inform his own historical and political discourses’ (Sherman, Dee, 91).
At the same time, even when equipped with (detailed) biographical information about a reader, the lack of interpretation on the part of the reader in turn renders topical notes difficult to interpret for scholars. Hence our inclination to focus on those marginal notes which are more verbose and informative in nature. However, such marginal notes represent only a small minority of the annotations that decorate the pages of most early modern books. Due to our focus on the relatively small number of interpretative notes, our research tends to be rather impressionistic in nature. But in general, topical notes abound: they litter the pages of the books owned by John Dee, while even a substantial number of annotations made by Gabriel Harvey, unusually verbose when annotating his books, are of the topical kind.
Data-driven approaches can be used to show the proliferation of topical notes and might offer a solution to overcome, at least partly, their limitations. A particularly revealing case is Dee’s copy of Ovid’s Ars Amatoria (Paris, 1529). Dee only annotated this book sparsely: he scribbled 181 marginal notes in the margins while he underlined approximately 4000 words of the printed text. Moreover, the average length of these marginal notes was 1.3 words, meaning that the majority of these notes just consisted of one word.
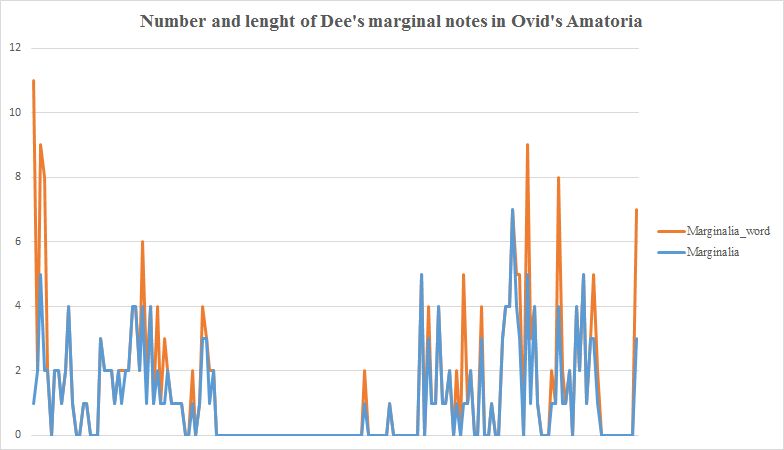
This is very little, even when compared to other books annotated by Dee and Harvey (bear in mind that the transcription work is ongoing and the figures in this overview are based on the statistics generated in late March 2018).
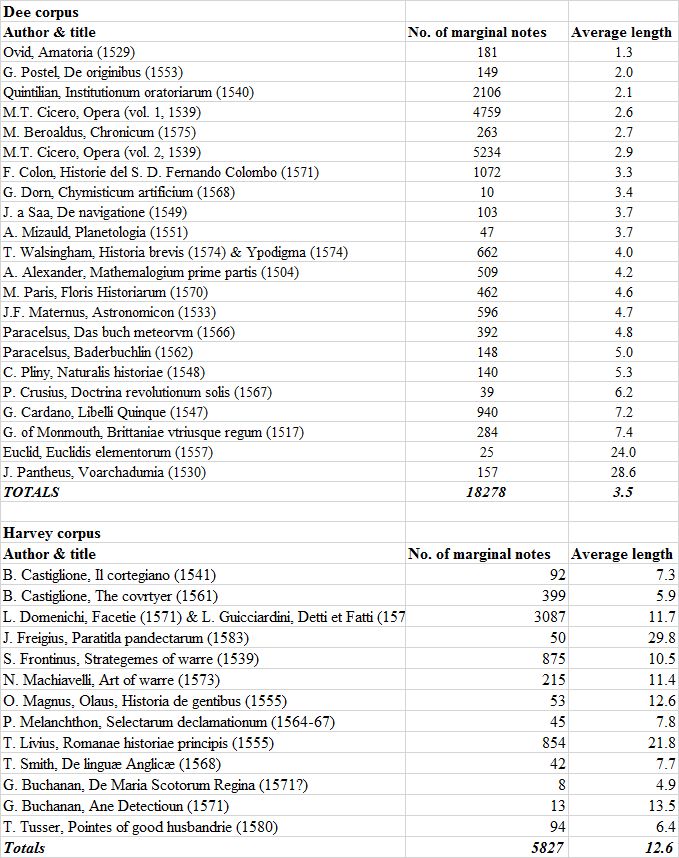
Some books clearly stand out. Dee’s copy of Euclid’s Elementorum, for example, only contained 25 annotations, but with an average length of almost 24 words (23.96). This average is greatly inflated by the appearance of a couple of lengthy marginal notes at the start of the book. The numbers relating to Dee’s copy of the Pantheus’ Voarchadumia are skewed as well: Dee interleaved this book with blank pages onto which he copied the text another tract by Pantheus, the Ars Metallicae. Because these interventions are treated as marginal annotations, the average number of words is greatly inflated. Harvey’s copy of Livy’s History of Rome, boasts a similar average (21.8 words), but based on an astonishing number of 854 annotations. Although massive annotations, such as one which consists of a staggering 718 words, helps to increase the average, the number of annotations which consists of one word are extremely limited: just 17 out of 854 annotations (almost 2%).


(Topical notes in Livy’s Ab urbe condita, p. 27, and Frontinus’ Strategemes, Gii).
In general, Harvey’s annotations were lengthier than those of Dee, as visible in the table above: Harvey’s average of 12.6 words against Dee’s average of 3.5 words.
Let’s return to the example we started with, Dee’s annotations in Ovid’s Ars Amatoria, and have look at the content of these short marginal annotations. When creating a list of the words and the frequency with which they appear, the results are everything but surprising: number one on the list is the word *drumroll* amor (or its declensions), which is mentioned 31 times. In the vast majority of cases, the marginal note solely comprises the word ‘Amor’. What to do with these marginal notes? Close reading is one possibility: which passages did Dee mark with this word and, just as significantly, which passages were not indicated by Dee in this manner. Such an analysis can be expanded by including other books which contain marginal annotations with the word ‘amor’. Such a ‘thematic’ search returns several hits for marginal notes in Cicero’s Opera and Quintilian’s Instititionum and can reveal a reader’s interest in a particular topic across his or her library.
Another, data-driven approach, would be to employ statistical analysis. This is a strand of AOR that we started to develop near the end of the first phase of the project (2014-6) which focused on Gabriel Harvey. Our approach is based on the creation of concept groups, consisting of words which are related to a specific topic, including war, kingship, eloquence, books, action, etc, and which appeared with a certain frequency in Harvey’s marginal annotations. After that we, and by we I mean professional statisticians, calculated whether or not there existed statistically significant correlations between concept groups. That is to say, the extent to which words which are part of one particular concept group appear in conjunction with words that are part of another. In this way, we can discern whether particular topics of interests were related to one another. As such, we are primarily interested in the intellectual patterns that appear in the marginal notes, not in the numbers generated by the statistical analysis themselves.
Although at present it is impossible to subject Dee’s annotations to such an analysis, simply because the transcription work is ongoing, we will be able to do so in a couple of months. By means of thematic searches and data-driven approaches such as statistical analysis, it might be possible to include some topical marginal notes into our scholarly investigations. Such data-driven approaches do not necessarily yield information about individual marginal notes: one-word notes, for example, cannot reveal a correlation between concept groups. However, topical notes are included in concept groups and hence figure in a larger thematic analysis.
We might be even able to expand the current statistical analysis: what happens when we start to study the correlation between books, people, and concept groups? Another possibility is to check the names of the people mentioned in marginal notes against the index of a particular book. Which people were and were not singled out by our readers? I mention these possibilities in order to make clear that there are strategies for the inclusion of topical notes in our analysis. Invariably, such strategies are time-consuming and will require a lot of work from the scholar. However, they might enable us to include a larger number of marginalia in our analysis and to get a more rounded understanding of historical reading practices and strategies.